Lesson 11: One Hot Encoding: No Strings
The final step before using the model is to transform all the data into numbers. You see, ML models can't work with string values like "php" or "Vilnius", which are also called "categorical" values.
Instead, the values should be numbers: 0, 1, 2, 3, ...
So, we could just replace the text values, numbering them from 0. But then, we wouldn't see clearly which programming language or city is which.
Instead, there's a better technique called One hot encoding, suitable especially in cases with only a few distinct values, like we have here.
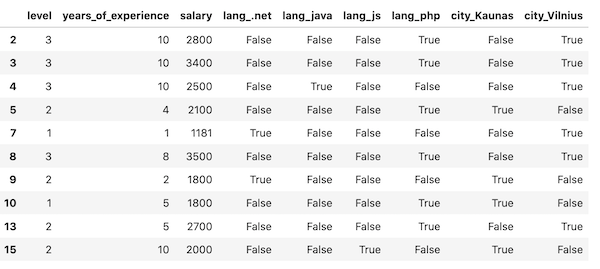
The logic is this: instead of having a column like language, we will have four columns, one for each programming language, with the value of True/False (or 1/0, if you prefer).
In other words, we will have columns like lang_php, lang_.net, etc.
Similarly, we will have columns like city_Vilnius and city_Kaunas.
There are a few ways to transform the data: with pandas or scikit-learn libraries, it's a personal preference. I will choose the first option with functions like pd.get_dummies(), df.join(), and df.drop():
main.py
1# ... 2 3plt.show() 4 5one_hot = pd.get_dummies(df['language'], prefix='lang') 6df = df.join(one_hot) 7df = df.drop('language', axis=1) 8 9one_hot = pd.get_dummies(df['city'], prefix='city')10df = df.join(one_hot)11df = df.drop('city', axis=1)12 13print(df.head(10))The code is self-explanatory: we get the new values, join them as columns, and then drop the old column. The parameter axis=1 means dropping the column and not the row.
Result:
Final File
If you felt lost in the code above, here's the final file with all the code from this lesson:
main.py
1import pandas as pd 2import numpy as np 3import matplotlib.pyplot as plt 4import seaborn as sns 5 6df = pd.read_csv('salaries-2023.csv') 7 8print(df.head()) 9print(df.shape)10df.info()11print(df.describe())12 13allowed_languages = ['php', 'js', '.net', 'java']14df = df[df['language'].isin(allowed_languages)]15 16vilnius_names = ['Vilniuj', 'Vilniua', 'VILNIUJE', 'VILNIUS', 'vilnius', 'Vilniuje']17condition = df['city'].isin(vilnius_names)18df.loc[condition, 'city'] = 'Vilnius'19 20kaunas_names = ['KAUNAS', 'kaunas', 'Kaune']21condition = df['city'].isin(kaunas_names)22df.loc[condition, 'city'] = 'Kaunas'23 24print(df.city.value_counts())25 26allowed_cities = ['Vilnius', 'Kaunas']27df = df[df['city'].isin(allowed_cities)]28print(df.shape)29 30df_sorted = df.sort_values(by='salary', ascending=False)31print(df_sorted.head(20))32 33x = df.iloc[:, -2:-1]34y = df.iloc[:, -1].values35plt.xlabel('Years of experience')36plt.ylabel('Salary')37plt.scatter(x, y)38plt.show()39 40df = df[df['salary'] <= 6000]41print(df.shape)42 43x = df.iloc[:, -2:-1]44y = df.iloc[:, -1].values45plt.xlabel('Years of experience')46plt.ylabel('Salary')47plt.scatter(x, y)48plt.show()49 50one_hot = pd.get_dummies(df['language'], prefix='lang')51df = df.join(one_hot)52df = df.drop('language', axis=1)53 54one_hot = pd.get_dummies(df['city'], prefix='city')55df = df.join(one_hot)56df = df.drop('city', axis=1)57 58print(df.head(10))Great, the final step before building the model is to decide whether we need all the features/columns. This is the topic of the next lesson.
- Intro
- Example 1: More Simple
- Example 2: More Complex
No comments or questions yet...