Lesson 1: What is Classification and What is Our Task
Welcome to this course about Classification tasks in Python and Machine Learning. We will look at a few real-life tasks, from simple to complex ones.
First, with a simple example, I want to show you what classification is.
Our First Simple Classification Task
Imagine you have a set of your tweets (or other social network posts) with their statistics of likes/retweets/replies:
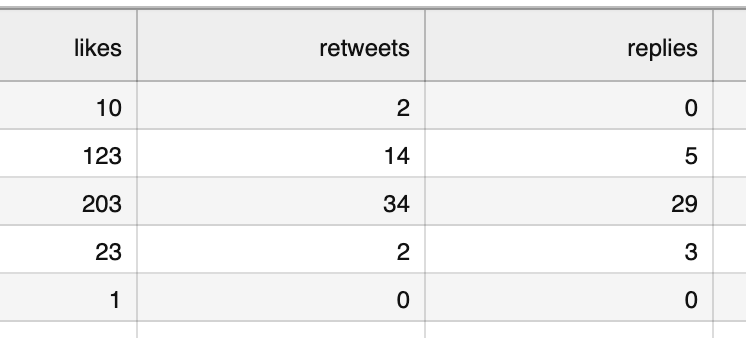
The client has manually picked the "viral" ones they want to re-post in the future, as they got the most engagement, so a new column appeared:
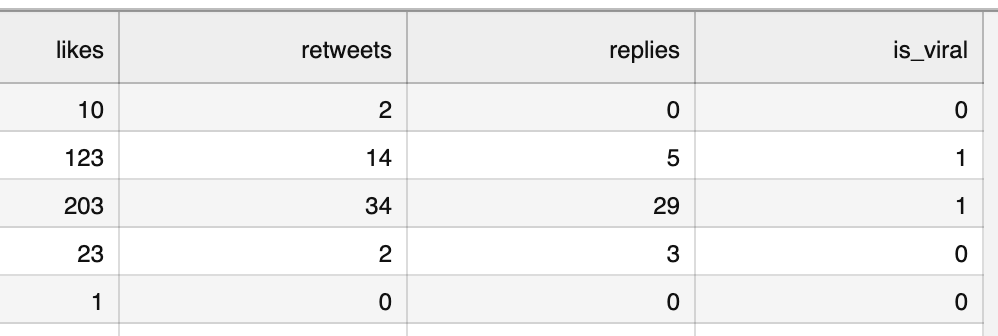
Now, the task is for us to build a Machine Learning Model that could learn from that data and then classify the future tweets as viral or not viral.
In other words, we need to auto-fill that last column is_viral for future tweets, based on their engagement. See the question mark signs below:
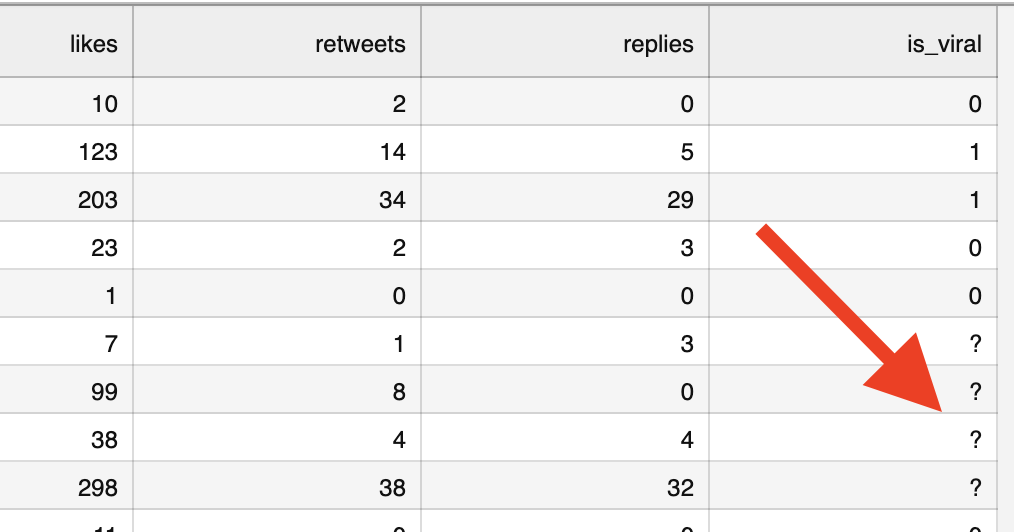
We don't have a formula or an if-statement for which tweets are actually considered viral. We need to train the ML model to decide it for us.
This is an example of a binary classification, with two different values for the data entry. Other examples may be:
- Yes/no answers: based on the email text and other past emails marked as spam, is the current email spam or not?
- A/B: based on the history of images, is this current image showing a dog or a cat?
- Harmful/harmless: based on the patient's medical data and other patients' historical data, are the symptoms harmful enough for hospitalization or not?
- Will/won't buy: based on a customer's previous purchases and other customers' behavior, will this customer buy a new product or not?
Overview of Algorithms
When building a Machine Learning model to predict the values, you will use different algorithms (also called "classifiers") from various Python libraries, like the ones we will cover in this course:
- Decision Trees and Random Forest
- K-Nearest Neighbors (often shortened to KNN)
- Support Vector Machines (shortened to SVM)
- Logistic Regression
- Naive Bayes
Some of these are not even algorithms but "families" of algorithms like Naive Bayes, with different specific implementations to choose from.
An ML engineer's main task is choosing the most appropriate algorithm for that specific task. There's no one-size-fits-all solution here. Different algorithms work better on specific sets of data, with specific end goals in mind and with varying constraints of time/accuracy.
Practical Project: Detect Viral Tweets with Random Forest
I'm a big fan of practical examples with a "quick success" goal to boost student motivation. So, instead of starting with a theoretical explanation of the algorithms, I will start with Python code that trains the model, and later we will discuss how it works.
For this first example of the tweets above, I chose a Random Forest classifier algorithm just to pick something for demonstration.
So, let's go build the model in the upcoming lessons.
-
- 1. What is Classification and What is Our Task
- 2. Read and Analyze Data
- 3. Split Data and Train/Build the Model
- 4. Classification Example with Multiple Categories
- 5. Random Forest and Decision Trees: Algorithms Explained
- 6. Text Classification and Vectors: Auto-Assign Product Category
- 7. Text Classification: Bigger CSV File and Other Algorithms
No comments or questions yet...