Lesson 6: Text Classification and Vectors: Auto-Assign Product Category
In the previous examples, we've been dealing with classification based on numbers that are quantifiable. But a more practical real-world task is to classify the text data, like auto-assigning a product category based on the product's name. Let's explore how it's done with the same Random Forest algorithm.
The Task: Auto-Classify Product Category
I've created a simple CSV file with the list of IT product models and their categories assigned manually:
The entire file is 87 lines long, with three possible categories.
Notice: you can view/download that CSV here.
Let's write the code to see that distribution:
import pandas as pd df = pd.read_csv("devices-products-small.csv") df.shape# Result: (87,2) df['Category'].value_counts()# Result:Categorycomputers 36tablets 29phones 22Name: count, dtype: int64Now, our task is to build a model to auto-assign the category for any NEW product, like "Samsung Galaxy S39" or whatever comes out in the future.
Typical Classification Doesn't Work with Text
We could, of course, try to use the same logic as in the previous lessons: create a classifier, train it, and make a prediction:
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier df = pd.read_csv("devices-products-small.csv") x = df['Product'].valuesy = df['Category'].values x_train, x_test, y_train, y_test = train_test_split(x, y) clf = RandomForestClassifier()clf.fit(x_train, y_train)But we will get an error on the fit() method:
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[135], line 2 1 clf = RandomForestClassifier()----> 2 clf.fit(x_train, y_train) ... (more error messages) --> 380 array = numpy.asarray(array, order=order, dtype=dtype) ValueError: could not convert string to float: 'iPad Air (5th generation)'As you can see, Python is unsuccessfully trying to convert the name of the iPad product into a float.
The thing is that people often forget that computers don't actually understand human language. They still work with numbers converted into 0s and 1s.
So, if we want to build a machine learning model, we need it to learn from a numerical representation of our data.
In other words, we need to manually convert those string product names into numbers that ML models would "understand".
There are various techniques for that, but in this lesson, we will use a so-called TF-IDF Vectorizer from a familiar library scikit-learn.
Words to Vectors
The letters "TF-IDF" stand for "Term Frequency - Inverse Document Frequency". It's an algorithm to transform texts into numbers. It builds the list of individual words from all the rows and assigns the importance value to each word, from 0 to 1.
To understand how it works, let's just apply the vectorizer and see the result:
from sklearn.feature_extraction.text import TfidfVectorizertfidf_vectorizer = TfidfVectorizer()tfidf_train_vectors = tfidf_vectorizer.fit_transform(x_train)The result of tfidf_train_vectors is a matrix. If you just try to show it, it won't say much to you:
<65x58 sparse matrix of type '<class 'numpy.float64'>' with 307 stored elements in Compressed Sparse Row format>So, let's explore it in other ways. Let's get the list of words (or "features") compiled into those vectors:
tokens = tfidf_vectorizer.get_feature_names_out()tokens# Result:array(['10', '11', '12', '13', '15', '16', '1st', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2nd', '3rd', '4th', '5th', '7th', '8th', 'air', 'early', 'edge', 'four', 'galaxy', 'generation', 'ii', 'iii', 'inch', 'ipad', 'late', 'macbook', 'mid', 'mini', 'ports', 'pro', 'retina', 's10', 's20', 's21', 's4', 's5', 's6', 's7', 's8', 's9', 'samsung', 'thunderbolt', 'two'], dtype=object)See? They are individual words of our list of products!
Now, let's build another DataFrame with pandas, assigning those feature names as column names:
tfidf_vectorizer = TfidfVectorizer()tfidf_train_vectors = tfidf_vectorizer.fit_transform(x_train) tokens = tfidf_vectorizer.get_feature_names_out()pd.DataFrame(data = tfidf_train_vectors.toarray(), columns = tokens)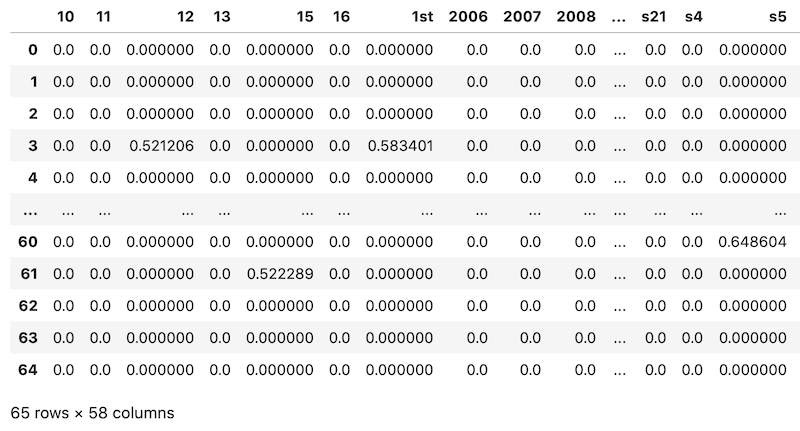
As you can see, most of those numbers are 0.000000, meaning "not important". Only some of those words have positive numbers of importance.
There's a mathematical explanation of how TF-IDF is calculated, but for now, what you practically need to know is that we can now pass those vectors into our ML model for classification.
Vectors into Classifier
So, let's get back to our initial script and finish the prediction:
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.feature_extraction.text import TfidfVectorizer df = pd.read_csv("devices-products-small.csv") x = df['Product'].valuesy = df['Category'].values x_train, x_test, y_train, y_test = train_test_split(x, y) tfidf_vectorizer = TfidfVectorizer()tfidf_train_vectors = tfidf_vectorizer.fit_transform(x_train)tfidf_test_vectors = tfidf_vectorizer.transform(x_test) clf = RandomForestClassifier()clf.fit(tfidf_train_vectors, y_train) # see - we're passing VECTORS herey_pred = clf.predict(tfidf_test_vectors) # here also vectors df_compare = pd.DataFrame( data={ 'product': x_test, 'predicted_category': y_pred, 'real_category': y_test }, columns=['product', 'predicted_category', 'real_category'])df_compare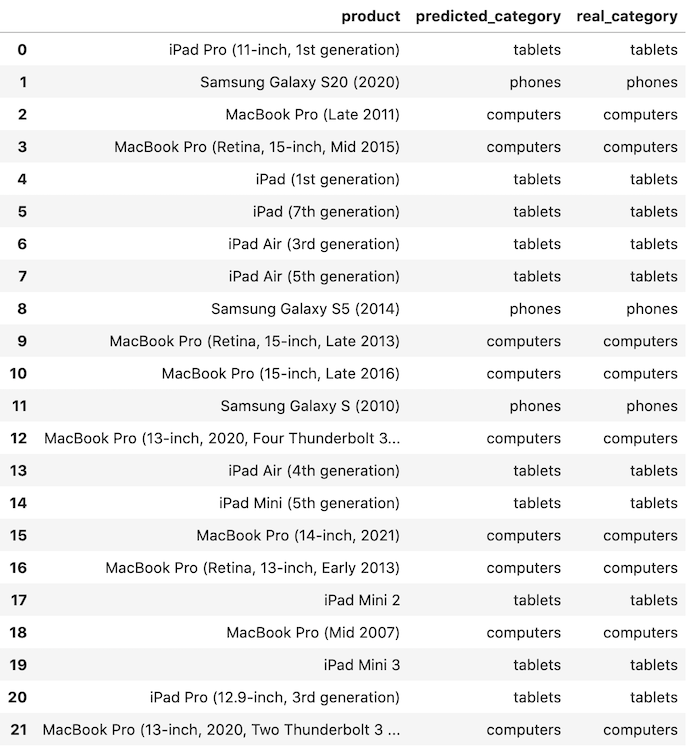
Looking at it visually, it seems correct!
What about the accuracy score?
from sklearn.metrics import accuracy_scoreaccuracy_score(y_test, y_pred) # Result: 1.0As expected, 100%!
Finally, let's test with our own string values: the same imaginary "Samsung Galaxy S39" I had mentioned at the beginning and a random "iPad" name.
But we can't pass it just as a string. We also need to vectorize it:
future_x_test = tfidf_vectorizer.transform(['Samsung Galaxy S39', 'iPad Future']) future_y_pred = clf.predict(future_x_test)future_y_pred# Result:array(['phones', 'tablets'], dtype=object)So yeah, the "Samsung Galaxy S39" is a phone, and the "iPad Future" is a tablet. Success! Our model seems to be working!
However, again, this data set is almost "ideal", so it's relatively easy to predict. But, I deliberately chose this simple example to demonstrate the concept of vectorizer and text classification.
In the next lesson, let's try this algorithm on a bit more complex CSV file.
-
- 1. What is Classification and What is Our Task
- 2. Read and Analyze Data
- 3. Split Data and Train/Build the Model
- 4. Classification Example with Multiple Categories
- 5. Random Forest and Decision Trees: Algorithms Explained
- 6. Text Classification and Vectors: Auto-Assign Product Category
- 7. Text Classification: Bigger CSV File and Other Algorithms
last script doesn't works because
clf_random_forest.have to beclf.the rest is very very great!
Well noticed, thanks! Fixed now.
Don't forget to import accuracy_score. from sklearn.metrics import accuracy_score
Thank you, well noticed! Added to the lesson.