Lesson 2: 02 - Read CSV into Documents and Embeddings
First, we need to load our initial knowledge base from the source: PDF, CSV files, database, or whatever format you have.
Also, since computers don't "understand" text but instead make calculations with numbers, we need to transform those texts into so-called embeddings.
So, in this lesson, we will focus on the top-right part of our main action plan:
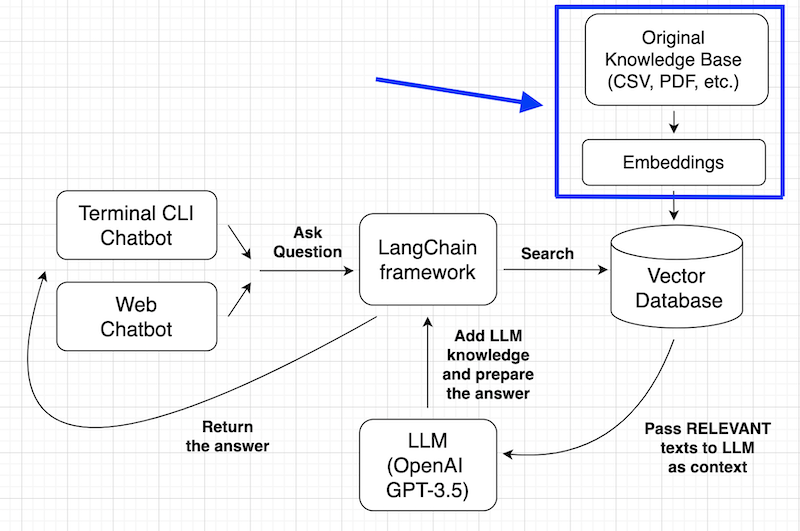
CSV into Documents with LangChain
To read CSV into a local variable, we could use a simple Python csv library. But let's make the format convenient for the future use.
So, this is where we meet the LangChain framework. It helps to work with Large Language Models by providing many methods to simplify the process.
You will see it in more action in the later lessons, but essentially, our chatbot code will have this as a pseudo-code:
from langchain.module1 import function1from langchain.module2 import function2from langchain.module3 import function3 function1(parameters)function2(parameters)function3(parameters)If we had to do it without LangChain, the same behavior would probably take dozens of lines of code to write.
So, it makes sense to start with LangChain CSVLoader from the beginning so that the data would be loaded into LangChain objects (called Documents) and not just Python lists.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path="faq.csv")documents = loader.load()print(documents)If you haven't yet installed LangChain on your computer, you can do it with pip install langchain.
This is the output:
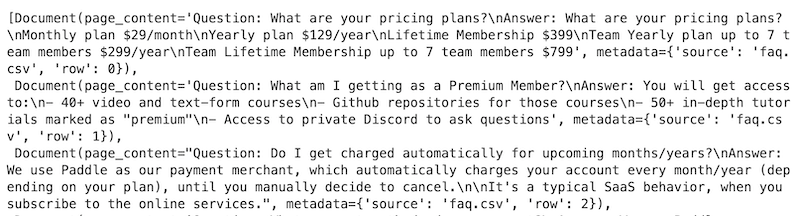
It's a Python list with elements of a Document class from LangChain.
It's not very human-readable, but it's great for the upcoming transformations. Since computers don't "understand" texts, we need to:
- Transform those documents into embeddings
- Store those embeddings in a vector database
Then, our chatbot would search that vector database and provide us with the answers to our questions.
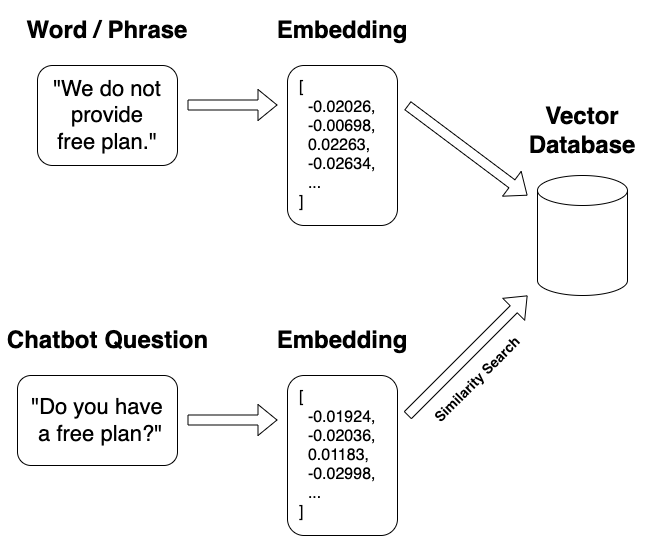
Let me explain the Embeddings a bit deeper.
Embeddings
Computers don't understand words and letters. They understand math and numbers. That's why we need to convert both the knowledge base and our chat message to a number format called embedding.
Embedding represents a string text (a paragraph, a sentence, a word) in a numbered vector.
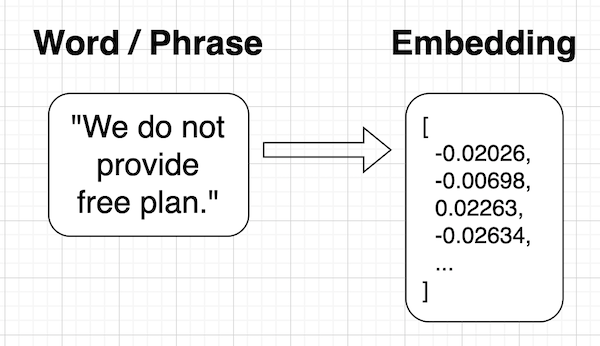
Such a format is not readable for humans, but it's a perfect fit for computers to calculate the similarity between words and phrases. This is exactly how the chatbot would be able to "understand" our questions and provide the answers with rephrased words.
There are various models for text embeddings, like Embeddings from OpenAI, which will be used in our project. Remember that it's not free (with limited free usage). Check out the Pricing page.
To interact with OpenAI Embeddings API, we will use Embeddings class from LangChain. It acts like a middleman between our knowledge base, embeddings, and the LLM.
In addition to OpenAI Embeddings, LangChain supports other embedding models like Hugging Face, Vertex AI, Cohere, and more. You can check the most popular ones in the article LangChain State of AI 2023.
With the help of LangChain, all we need to do is import and create the object, passing the OpenAI API key:
from langchain.document_loaders.csv_loader import CSVLoaderfrom langchain_openai import OpenAIEmbeddings loader = CSVLoader(file_path="faq.csv")documents = loader.load() embeddings_model = OpenAIEmbeddings(openai_api_key='sk-...') You can create/get that API Key in your OpenAI account.
Notice: to use OpenAIEmbeddings, we also need to install one Python library called tiktoken. You can do that with pip install tiktoken.
Now, let's try to transform some random texts to embeddings:
# Just an example from the official docs:embeddings = embeddings_model.embed_documents( [ "Hi there!", "Oh, hello!" ])print(embeddings)# Output:[[-0.020262643931117454, -0.006984279861728337, -0.022630838723440946, -0.02634143617913019, -0.03697932214749123, 0.021389752772190157, # ... many (MANY!) more numbers]]Again, not readable for humans? But it's perfect for machines.
Note that there are text length limitations for embeddings: in the case of OpenAI Embeddings, it's roughly about 10 pages of text. So, if you have longer text, like PDF documents, you need to split it into pieces (pages) and embed them individually with CharacterTextSplitter from LangChain or other functions. We will not cover that splitting in the current tutorial, because our case of CSV is simple and doesn't need it.
In the next lesson, we will use embeddings on our real CSV data. In fact, we won't need to create them manually, LangChain will take care of it for us.
Also, in the next lesson, we will store the embeddings in a vector database.
Can you share the csv?
Full code, including CSV, is in this repository, provided at the end of the last lesson.