Lesson 3: 03 - Embeddings into Vector Database with FAISS
In this lesson, we will focus on this part of our global plan:
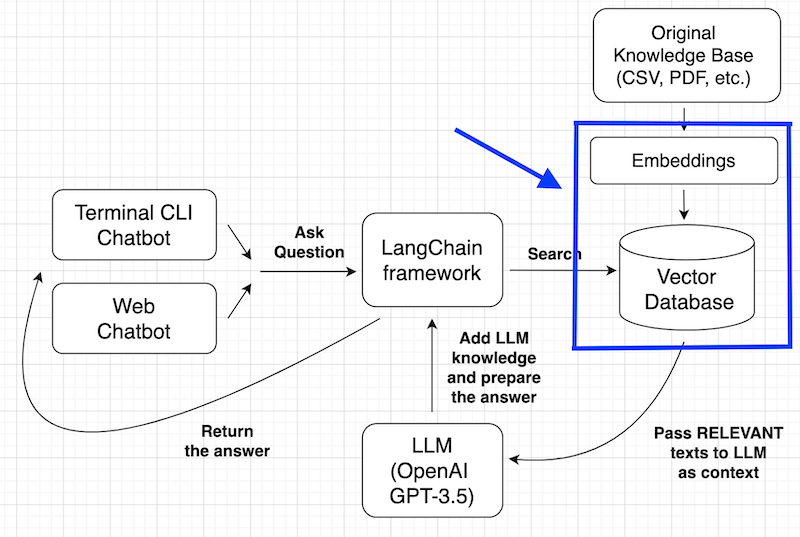
With the help of LangChain, we don't need to build the embeddings manually and call the embed_documents() function as we did in the last lesson.
We can create a vector database object and store the embeddings directly from the documents:
from langchain.document_loaders.csv_loader import CSVLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISS loader = CSVLoader(file_path="faq.csv")documents = loader.load() embeddings_model = OpenAIEmbeddings(openai_api_key='sk-...') vectorstore = FAISS.from_documents(documents, embeddings_model) Wait, what's that FAISS?
OpenAI provides the embedding mechanism but not the space to store those embeddings. So, we need to choose from other additional tools. Similarly to embeddings, there are plenty of options for storing vectors:
- FAISS by Facebook (we will use it in this tutorial)
- Pinecone
- Chroma
- Weaviate
- ... many more
Some of those are specific vector databases, others are more general database systems that can store vectors. You can check the most popular vector databases in the article LangChain State of AI 2023.
In our case, we will use FAISS. You must install it in your system with pip install faiss-cpu. There's also a faiss-gpu version if you have a powerful enough GPU and want to utilize it.
As a result, we now have a vectorstore object which allows us to perform the similarity search in a vector database:
results = vectorstore.similarity_search('Do you have a free plan?')print(results)# Output:[ Document(page_content='Question: What are your pricing plans?\nAnswer: What are your pricing plans?\n ...', metadata={'source': 'faq.csv', 'row': 0}), Document(page_content="Question: Do I get charged automatically for upcoming months/years?\nAnswer: We use Paddle ...", metadata={'source': 'faq.csv', 'row': 2}), Document(page_content='Question: Any discount coupons based on country? PPP?\nAnswer: Yes. All Purchasing Power Parity ...', metadata={'source': 'faq.csv', 'row': 5}), Document(page_content='Question: What am I getting as a Premium Member?\nAnswer: You will get access to:\n- 40+ video...', metadata={'source': 'faq.csv', 'row': 1})]As you can see, the similarity search returns the documents from the list above that were found to be similar to the text query. Again, the search is based on vector embeddings, not string texts.
But for the chatbot, we won't need to perform this similarity_search() manually. Again, LangChain will do it for us behind the scenes. We just need to provide the vectorstore variable, and LangChain will call the LLM (OpenAI GPT-3.5-Turbo), passing those filtered documents as so-called context.
To provide the answer to the chatbot query, the OpenAI GPT will use the internal information it has been trained on but also will use our documents as additional (or, rather, primary) context.
We will implement all of that in the next lesson. So, time to actually use the OpenAI API?
LangChainDeprecationWarning: Importing vector stores from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:
from langchain_community.vectorstores import FAISS.To install langchain-community run
pip install -U langchain-community.And: LangChainDeprecationWarning: The class
langchain_community.embeddings.openai.OpenAIEmbeddingswas deprecated in langchain-community 0.1.0 and will be removed in 0.2.0. An updated version of the class exists in the langchain-openai package and should be used instead. To use it runpip install -U langchain-openaiand import asfrom langchain_openai import OpenAIEmbeddingsEnded up with:
Yeah, that's the thing with those libraries: they constantly change and deprecate things.
Good notice!