Lesson 4: 04 - OpenAI GPT and First Chatbot Response
In this lesson, we will focus on this part of our global plan:
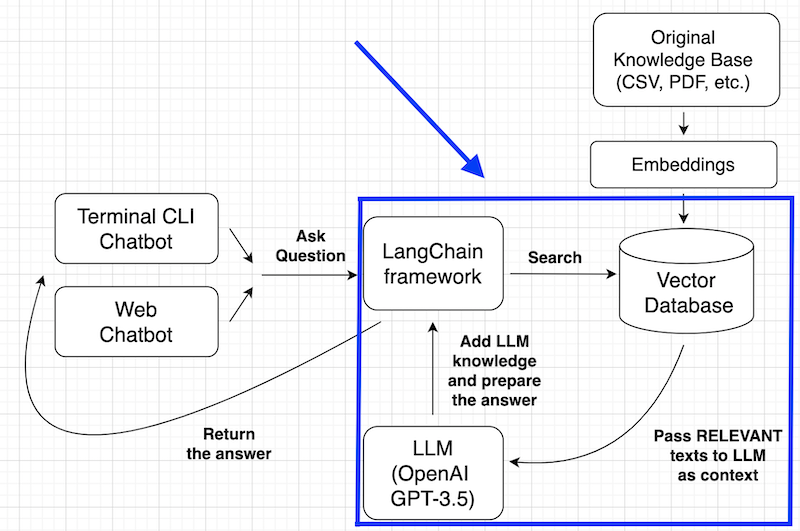
We will finally ask the chatbot and get a real answer.
Use OpenAI LLM via LangChain
To actually "talk" to the chatbot, we need to use two classes from LangChain:
-
LLM class: in our case,
ChatOpenAI() -
Chain class: in our case,
ConversationalRetrievalChain()
First, the OpenAI LLM model.
from langchain.document_loaders.csv_loader import CSVLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_openai import ChatOpenAI loader = CSVLoader(file_path="faq.csv")documents = loader.load() embeddings_model = OpenAIEmbeddings(openai_api_key='sk-...') vectorstore = FAISS.from_documents(documents, embeddings_model) llm_model = ChatOpenAI(openai_api_key='sk-...') Behind the ChatOpenAI(), we will use the same LLM as ChatGPT does internally (GPT-3.5-Turbo) but will call it programmatically via API from our script. It also allows us to pass the personal context of our documents via the same API.
Notice: using the OpenAI API GPT model is not free. Check the OpenAI Pricing Page.
Build a Conversation Chain via LangChain
Next, we build that conversation chain class, passing two parameters to it:
- The LLM object from above
- Our
vectorstorethat we had created in the previous lesson - in this case, it will be called a "retriever"
from langchain.document_loaders.csv_loader import CSVLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_openai import ChatOpenAIfrom langchain.chains import ConversationalRetrievalChain loader = CSVLoader(file_path="faq.csv")documents = loader.load() embeddings_model = OpenAIEmbeddings(openai_api_key='sk-...') vectorstore = FAISS.from_documents(documents, embeddings_model) llm_model = ChatOpenAI(openai_api_key='sk-...') chain = ConversationalRetrievalChain.from_llm(llm=llm_model, retriever=vectorstore.as_retriever()) By default, the vector store retriever uses the similarity search that we discussed above. You may also specify the number of documents returned:
# Return 3 most relevant documentsvectorstore.as_retriever(search_kwargs={"k": 3})It may lower the amount of context sent to the OpenAI API. In other words, you may pay a smaller price for the request.
Finally: Ask The Chatbot
After all those preparations, we can launch that chain by asking our chatbot a question.
We need to pass two parameters: the question itself and then the chat history, which is currently empty.
from langchain.document_loaders.csv_loader import CSVLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_openai import ChatOpenAIfrom langchain.chains import ConversationalRetrievalChain loader = CSVLoader(file_path="faq.csv")documents = loader.load() embeddings_model = OpenAIEmbeddings(openai_api_key='sk-...') vectorstore = FAISS.from_documents(documents, embeddings_model) chain = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(openai_api_key='sk-...'), retriever=vectorstore.as_retriever()) query = "Do you have a team plan?" response = chain.invoke({"question": query, "chat_history": []}) print(response) Hey, we have the first actual response from our chatbot!
# Output:{'question': 'Do you have a team plan?', 'chat_history': [], 'answer': 'Yes, we do have a team plan. The team plan is available in two options: the Team Yearly plan, which costs $299/year and can accommodate up to 7 team members, and the Team Lifetime Membership, which costs $799 and also allows for up to 7 team members.'}But wait, how much this response cost us?
Calculating Cost of OpenAI Requests
You can, of course, look at your OpenAI Usage dashboard:
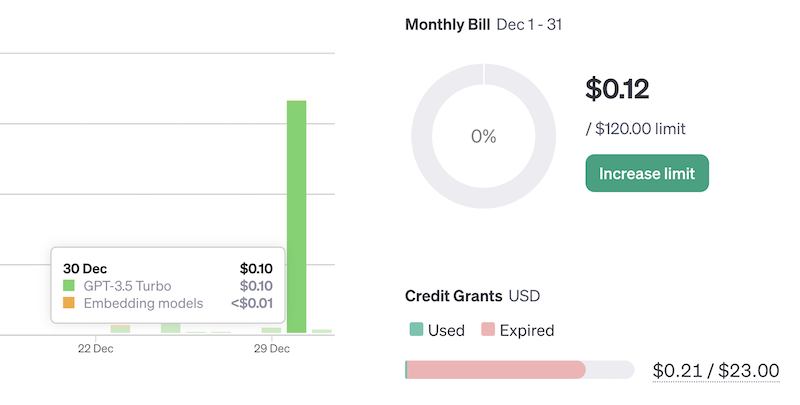
The problem is that it doesn't refresh in real time or show the numbers for individual API requests.
Instead, you can get the stats for a specific request directly in the code. LangChain has a function for it, called get_openai_callback():
from langchain.callbacks import get_openai_callback query = "Do you have a team plan?" with get_openai_callback() as cb: response = chain.invoke({"question": query, "chat_history": []}) print(cb)# Output:Tokens Used: 297 Prompt Tokens: 247 Completion Tokens: 50Successful Requests: 1Total Cost (USD): $0.0004705So yeah, this chatbot question cost us 0.04 dollar cents. Not a lot, right? But the reason is that the question is very short/simple, and our knowledge base is tiny.
Again, for token prices, check the official OpenAI Pricing page.
Bonus Refactoring: OpenAI API Key To Environment
At the end of this lesson, it is time for a small refactoring. You may have noticed that we repeat the API key twice: once for embeddings and also for the LLM model. Let's change it and add that variable to the environment:
import os os.environ["OPENAI_API_KEY"] = 'sk-...' # ... all the other script vectorstore = FAISS.from_documents(documents, OpenAIEmbeddings()) chain = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(), retriever=vectorstore.as_retriever())Now we don't need to pass the parameter of the OpenAI API Key, as those objects will try to find it in the environment, with the key of OPENAI_API_KEY.
Also, we can call the OpenAIEmbeddings() and ChatOpenAI() directly as parameters of other functions instead of creating local variables.
As one of the takeaways from the lessons so far, you see how much work the LangChain framework performs for us. And even that is not all. It will help us with memory management, let's tackle that in the next lesson.
Some deprecation and conflicting-version issues here.
Here below the updated imported libraries:
Working 'conflicting-free' versions (generated via
pip freeze):and
become
These generate clean and no-warnings output.
Hi, thanks for the note - we have updated the lessons and will shortly update our demo repository!
Same thing for:
that become