Python OCR: Invoice Data from PDF/Image - 4 Libraries Tested

One of the most typical Machine Learning tasks is reading structured text from images with OCR. We experimented with 5 sample invoices, trying to read the data using a few Python libraries. Let's see how they work.
First, the original invoice:
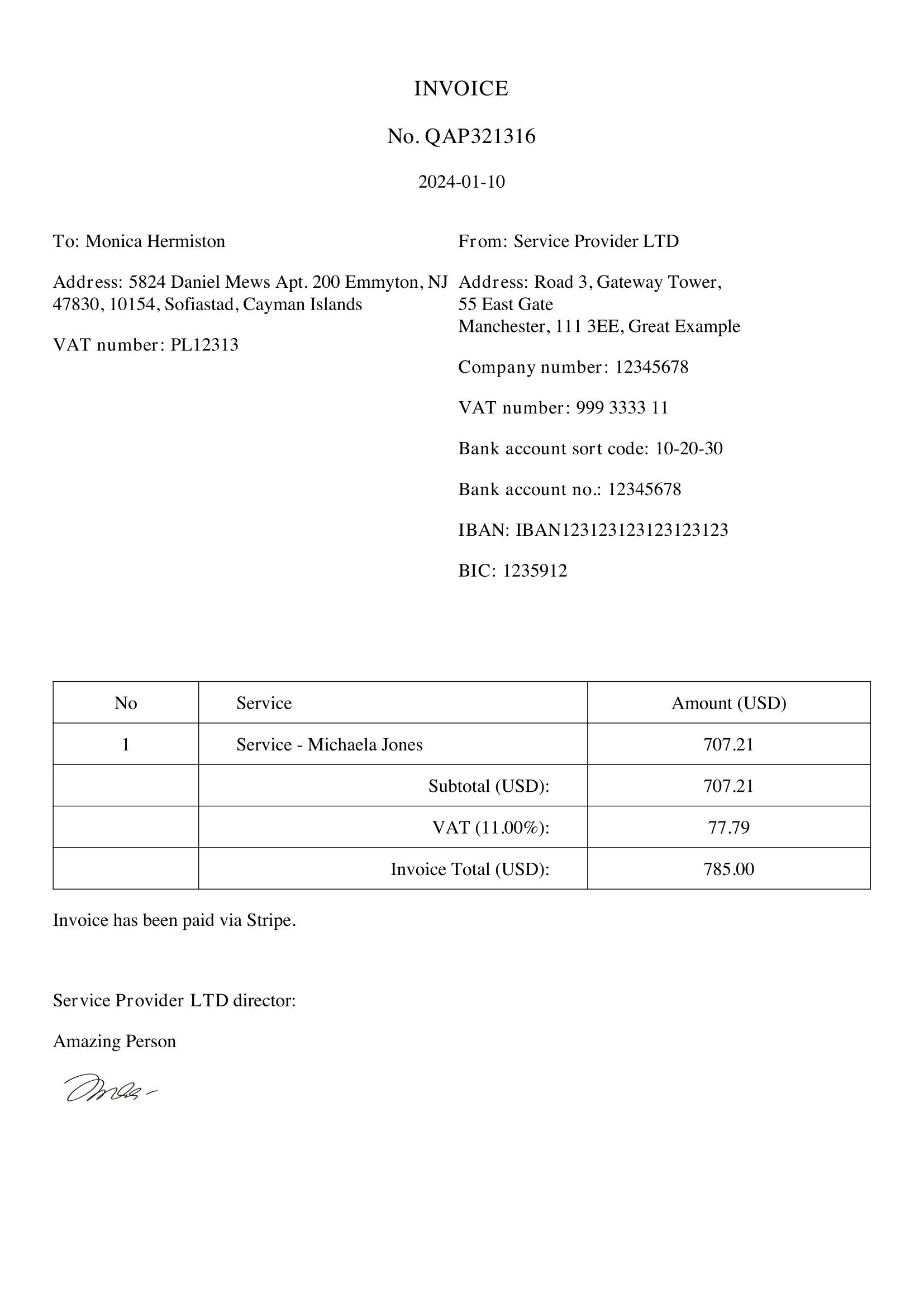
Our goal is to read the parts into a structure for further analysis: customer data, items purchased, etc.
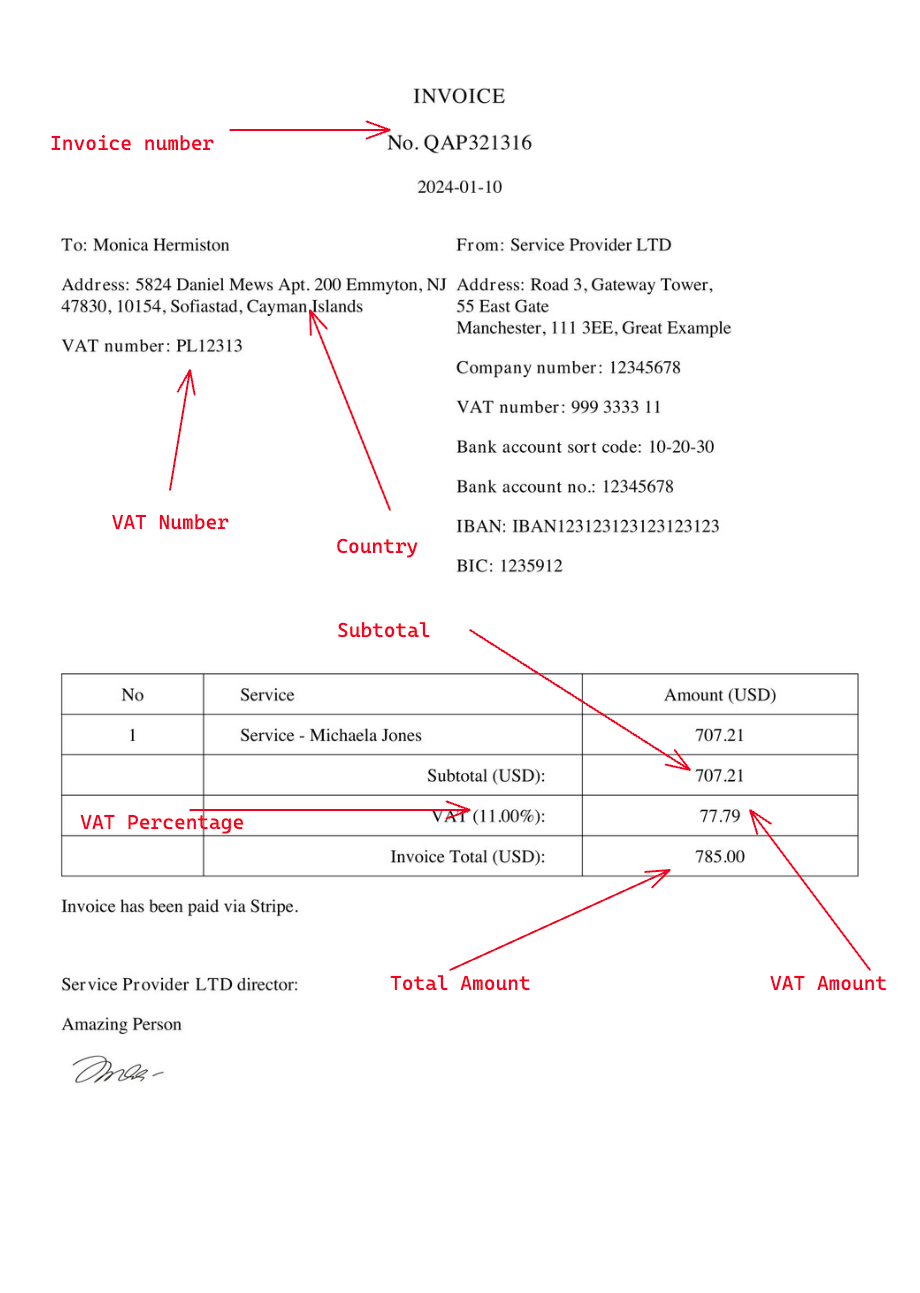
And we will tackle two scenarios:
- If you have the invoice as a PDF file (PDF To Text)
- If you have it as an image file (OCR)
Table of Contents
- Reading from PDF with PDFToText Library
- Converting PDF to Image with pdf2image
- OCR: Reading Image with Pytesseract
- Alternative 1: EasyOCR
- Alternative 2: Keras OCR
Let's go!
Reading from PDF with PDFToText Library
Our first example will use the PDFToText library, which is not an actual OCR but an excellent place to start.
First, we need to install the library:
pip install pdftotextWith this library, you will receive the text from your PDF file (just like copy-pasting it) without any structure. Let's look at the Python code:
import globimport pdftotext # Get all PDF files in the invoices folderfiles = glob.glob('invoices/*.pdf') for i, file in enumerate(files): with open(file, 'rb') as f: # Raw=True is needed to get text grouped together # which improves the accuracy pdf = pdftotext.PDF(f, raw=True) text = '\n\n'.join(pdf) print(text)With this, we will get the text output from the PDF like this:
INVOICENo. QAP3213162024-01-10To: Monica HermistonAddress: 5824 Daniel Mews Apt. 200 Emmyton, NJ47830, 10154, Sofiastad, Cayman IslandsVAT number: PL12313From: Service Provider LTDAddress: Road 3, Gateway Tower,55 East GateManchester, 111 3EE, Great ExampleCompany number: 12345678VAT number: 999 3333 11Bank account sort code: 10-20-30Bank account no.: 12345678IBAN: IBAN123123123123123123BIC: 1235912No Service Amount (USD)1 Service - Michaela Jones 707.21Subtotal (USD): 707.21VAT (11.00%): 77.79Invoice Total (USD): 785.00Invoice has been paid via Stripe.Service Provider LTD director:Amazing PersonThen comes the second part of the job: use regular expressions to parse the text into a structure. In the code below, we basically just call re.search() a lot of times:
import globimport pdftotextimport re data_output = [ [ 'Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount', ]] # This uses glob to get all PDF files in the invoices folder automaticallyfiles = glob.glob('invoices/*.pdf') for i, file in enumerate(files): with open(file, 'rb') as f: # Raw=True is needed to get text grouped together # which improves the accuracy pdf = pdftotext.PDF(f, raw=True) text = '\n\n'.join(pdf) invoice_number = re.search(r'No.\s*(.+?)\s*\n', text).group(1).strip() # Find full address box between Address: and From: address_box = re.search(r'Address:\s*([\s\S]*?)\s*From:', text).group(1) # Remove VAT number from address box (if it exists) address_box = re.sub(r'VAT number:.*?(\n|$)', '', address_box) # Get last word from address box, which is the country country = ' '.join(address_box.split(' ')[-1].strip().split('\n')) subtotal_amount = re.search(r'Subtotal \(USD\):\s*(.+?)\s*\n', text).group(1).strip() search_vat_number = re.search(r'VAT number:\s*(.+?)\s*\n', text) if search_vat_number and search_vat_number.group(1) != '999 3333 11': vat_id_number = search_vat_number.group(1).strip() else: vat_id_number = None vat_information = re.search(r'VAT \((.+?)%\):\s*(.+?)\s*\n', text) vat_percent = vat_information.group(1).strip() vat_amount = vat_information.group(2).strip() total_amount = re.search(r'Invoice Total \(USD\):\s*(.+?)\s*\n', text).group(1).strip() data_output.append([ invoice_number, country, subtotal_amount, vat_id_number, vat_percent, vat_amount, total_amount, ]) print(data_output)The output will be:
[ ['Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount'], ['QAP321316', 'Islands', '707.21', 'PL12313', '11.00', '77.79', '785.00'], ['QAP321317', 'Cathy, Bahamas', '66.68', 'NL123125', '15.23', '10.16', '76.84'], ['QAP321320', 'Turkey', '111.79', 'IT123156', '6.05', '6.76', '118.55'], ['QAP321319', 'Helena', '289.40', 'FR542122', '1.65', '4.78', '294.18'], ['QAP321318', 'Bahrain', '13.64', 'DE969696', '12.62', '1.72', '15.36']]Great, right?
But there might be some issues with this approach:
- We need to know the exact structure of the PDF
- We need to write a lot of Regexes, which can be tricky: invoices can have more/fewer data points, it's hard to make it work for all cases
With that in mind, we have a few failures in our example:
['QAP321316', 'Islands', '707.21', 'PL12313', '11.00', '77.79', '785.00'],The country is not parsed correctly because we did not structure the Regex to handle the case if there is a multi-word country name.
So, conclusion so far: reading the PDF into text is the easy part of this task. The more important part is parsing the text into the data structure.
As for the speed of reading PDFs, here's the result:
Runtime: 0.02s user 0.02sIt ran incredibly fast, but that's because we only had 5 invoices. Also, it's reading from the PDF and not from the image, to the real OCR is much slower, as we will see in the examples below.
Converting PDF to Image with pdf2image
Of course, in real world, not all invoices come as a PDF, you often need to work with images: PNGs, JPGs, etc.
Before diving into the OCR world, we need to prepare the input images. So, let's transform our PDFs into JPG files.
Let's install the library:
pip install pdf2imageAnd now, we can call it from Python:
import glob from pdf2image import convert_from_path invoices = glob.glob('invoices/*.pdf') for i, invoice in enumerate(invoices): # Store Pdf with convert_from_path function # use_pdftocairo=True is faster than the default `poppler` library images = convert_from_path(invoice, use_pdftocairo=True) for j in range(len(images)): # Save pages as images in the pdf invoice_name = invoice.split('.')[0].split('/')[1] images[j].save('invoices_images/' + invoice_name + '-page' + str(j) + '.jpg')It is as simple as that. We will take any invoices from the invoices folder and save them as images in the invoices_images folder. This used glob to get all PDF files and then pdf2image to convert them.
Important thing to notice: this code worked with the latest Python 3.12. But when we tried with an older Python 3.9, we got an error message:
(1, 'Corrupt JPEG data: premature end of data segment Error in pixReadStreamJpeg: read error at scanline 2334; nwarn = 1 Error in pixReadStreamJpeg: bad data Error in pixReadStream: jpeg: no pix returned Leptonica Error in pixRead: pix not read:This is a general thing with Python libraries: some of them work (best) with specific Python versions.
OCR: Reading Image with Pytesseract
We have finally reached the OCR part. For this demo, we will use the Pytesseract library, a wrapper for Google's Tesseract-OCR Engine. It's a popular library, and it's easy to use, so let's get started with the installation:
pip install pytesseractThen, before we can use it, we need to install the Tesseract-OCR Engine. You can find the installation instructions here.
Note: This is required as the actual OCR engine will read the text from the image. Pytesseract is just a wrapper for it.
Once that is done, we can write our code:
import globimport pytesseract img = glob.glob('invoices_images/*.jpg') for i, image in enumerate(img): text = pytesseract.image_to_string(image, lang='eng') print(text)Now, let's see what this code does:

It simply read the text from the image, and we could print it out. But let's compare it to the original invoice:
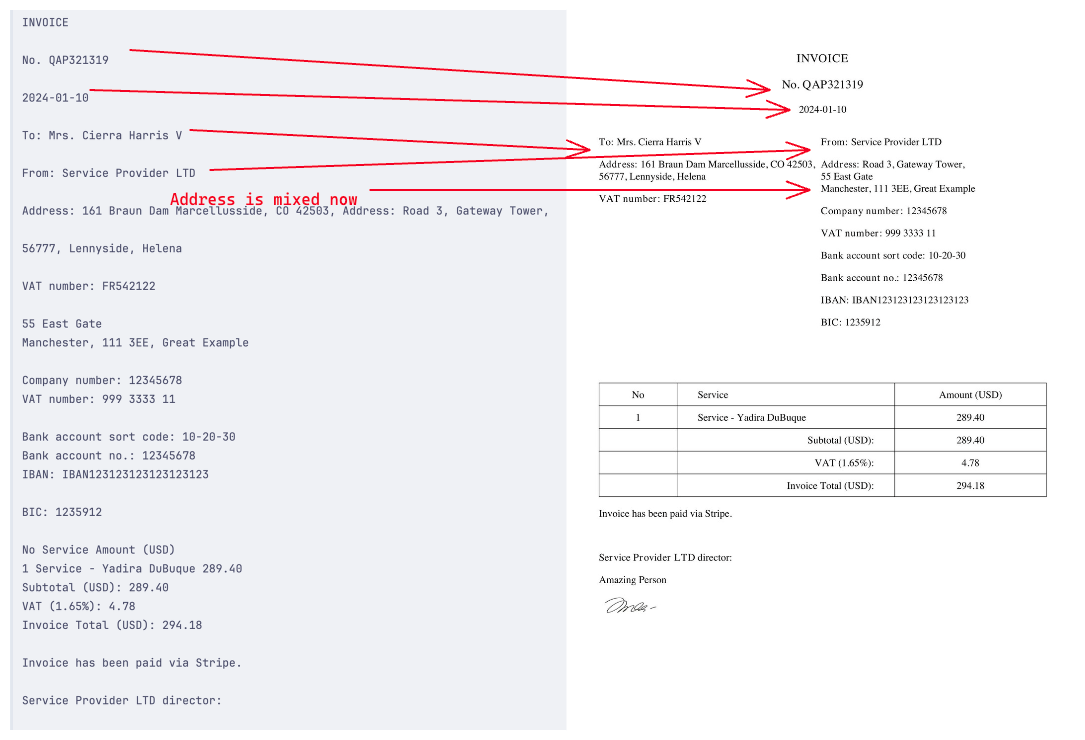
There are some things out of place. For example, as mentioned in the image - our address is not in the order we expected. It is mixing our From and To address information, which... Causes some issues. We must remember this when working with OCR - it sometimes works in different ways than we read it. Here are a few reasons for it:
- The image needs to be clearer. Sometimes, the image is just unclear to the OCR, and it guesses random things.
- The image has small spaces between text blocks. This can confuse the OCR, and it will read it as a new text block.
- And some other things you can prevent by doing some image pre-processing.
That said, we can still work out the structure of the invoice. Of course, this involves a lot of Regex, but it usually comes to this when working with OCR. Here's how we approached it:
import globimport pytesseractimport re data_output = [ [ 'Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount', ]] img = glob.glob('invoices_images/*.jpg') for i, image in enumerate(img): text = pytesseract.image_to_string(image, lang='eng') invoice_number = re.search(r'No.\s*(.+?)\s*\n', text).group(1).strip() country = re.search(r'Address:\s*(.+?)\s*\n\n', text, re.DOTALL).group(1).split(',')[-1].strip() country = country.replace('32 Western Gateway', '').strip() subtotal_amount = re.search(r'Subtotal \(USD\):\s*(.+?)\s*\n', text).group(1).strip() search_vat_number = re.search(r'VAT number:\s*(.+?)\s*\n', text) if search_vat_number and search_vat_number.group(1) != '999 3333 11': vat_id_number = search_vat_number.group(1).strip() else: vat_id_number = None vat_information = re.search(r'VAT \((.+?)\):\s*(.+?)\s*\n', text) vat_percent = vat_information.group(1).replace('%', '').strip() vat_amount = vat_information.group(2).strip() total_amount = re.search(r'Invoice Total \(USD\):\s*(.+?)\s*\n', text).group(1).strip() data_output.append([ invoice_number, country, subtotal_amount, vat_id_number, vat_percent, vat_amount, total_amount, ]) print(data_output)Once we ran this on our example invoices, we got this output:
[ ['Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount'], ['QAP321319', '', '289.40', 'FR542122', '1.65', '4.78', '294.18'], ['QAP321320', 'Turkey', '111.79', 'IT123156', '6.05', '6.76', '118.55'], ['mystad, IL', 'Bahrain', '13.64', 'DE969696', '12.62', '1.72', '15.36'], ['QAP321316', 'Great Example', '707.21', 'PL12313', '11.00', '71.79', '785.00'], ['QAP321317', '', '66.68', 'NL123125', '15.23', '10.16', '76.84']]As you can see, it is very similar to the PDFToText example, but the difference is that we read this from an image, and we do have a few mistakes. These mistakes should be solved by Regex adjustments, but we will leave that out here.
Speed and Accuracy
Of course, we have to talk about the speed. It is considerably slower than PDFToText, but it makes sense. We got an average of:
Runtime: 3.28s user 1.93sAnd while this is insanely slower than PDFToText - it is expected. OCR is much more complex, and it must read the image entirely. For example, our PDF-to-text never found this, but OCR managed to read it:

This can be more valuable than speed, depending on your use case. While we parsed invoices, you can use OCR for something else. You might even want to parse semi-obstructed photos, where OCR shines. So, it all depends on your use case.
When doing this tutorial, we tried a few other OCR libraries but had different levels of success/issues. Let's look at them in case you want to try them out.
Alternative 1: EasyOCR
We tried using the EasyOCR library, but that didn't work well with the latest Python 3.12, it seems to be incompatible:
ERROR: Cannot install easyocr==1.0, easyocr==1.1, easyocr==1.1.1, easyocr==1.1.10, easyocr==1.1.2, easyocr==1.1.3, easyocr==1.1.4, easyocr==1.1.5, easyocr==1.1.6, easyocr==1.1.7, easyocr==1.1.8, easyocr==1.1.9, easyocr==1.2, easyocr==1.2.1, easyocr==1.2.2, easyocr==1.2.3, easyocr==1.2.4, easyocr==1.2.5, easyocr==1.2.5.1, easyocr==1.3, easyocr==1.3.0.1, easyocr==1.3.1, easyocr==1.3.2, easyocr==1.4, easyocr==1.4.1, easyocr==1.4.2, easyocr==1.5.0, easyocr==1.6.0, easyocr==1.6.1, easyocr==1.6.2, easyocr==1.7.0 and easyocr==1.7.1 because these package versions have conflicting dependencies.ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/topics/dependency-resolution/#dealing-with-dependency-conflictsWe have tried 3.11, 3.10 and still encountered some issues, so we finally installed EasyOCR only with Python 3.9.
Then, we could write the code for it:
pip install easyocrpip install pandasAnd here's the code:
import easyocrimport pandas as pdimport glob img = glob.glob('invoices_images/*.jpg') for i, image in enumerate(img): reader = easyocr.Reader(['en'], gpu=True) results = reader.readtext( image, # Paragraph is needed to get text grouped together paragraph=True, # X_threshold is needed to get text grouped together # For example, address fields with high X_threshold will be grouped together # and will be returned as one text. This is not the desired outcome. # Lowering the X_threshold will return the address fields as separate text, which is also bad! # PS. Play around with the X_threshold to see the results. x_ths=0.3 ) df = pd.DataFrame(results, columns=['bbox', 'text']) print(df.head())With this, we were able to get the text from the image:

We received two columns there:
-
bbox- Is the bounding box of the text (rectangle coordinates around the text) -
text- Is the text itself
From there, we were able to retrieve the text and form it into a single big text block for Regex matching:
import easyocrimport pandas as pdimport globimport re data_output = [ [ 'Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount', ]] img = glob.glob('invoices_images/*.jpg') for i, image in enumerate(img): reader = easyocr.Reader(['en'], gpu=True) results = reader.readtext( image, # Paragraph is needed to get text grouped together paragraph=True, # X_threshold is needed to get text grouped together # For example, address fields with high X_threshold will be grouped together # and will be returned as one text. This is not the desired outcome. # Lowering the X_threshold will return the address fields as separate text, which is also bad! # PS. Play around with the X_threshold to see the results. x_ths=0.3 ) df = pd.DataFrame(results, columns=['bbox', 'text']) df.drop(columns=['bbox'], inplace=True) text = '\n\n'.join(df['text'].tolist()) invoice_number = re.search(r'No.\s*(.+?)\s*\n', text).group(1).strip() country = re.search(r'Address:\s*(.+?)\s*\n\n', text, re.DOTALL).group(1).split(',')[-1].strip() subtotal_amount = re.search(r'Subtotal \(USD\):\s*(.+?)\s*\n', text).group(1).strip() search_vat_number = re.search(r'VAT number:\s*(.+?)\s*\n', text) if search_vat_number and search_vat_number.group(1) != '999 3333 11': vat_id_number = search_vat_number.group(1).strip() else: vat_id_number = None # Our OCR reader sometimes treats % as 9... So our Regex needs [%9] to match both vat_information = re.search(r'VAT \((.+?[%9])\):\s*(.+?)\s*\n', text) if not vat_information: # Sometimes, it decides to not treat `0.00` as a number, so we need to handle that print('VAT information not found for invoice: ' + image) vat_percent = 0 vat_amount = 0 else: vat_percent = vat_information.group(1).strip() vat_amount = vat_information.group(2).strip() total_amount = re.search(r'Invoice Total \(USD\):\s*(.+?)\s*\n', text).group(1).strip() data_output.append([ invoice_number, country, subtotal_amount, vat_id_number, vat_percent, vat_amount, total_amount, ]) print(data_output)This gave us a combined text that looked like this:
INVOICE No. QAP321319 2024-01-10 To: Mrs. Cierra Harris V From: Service Provider LTD Address: 161 Braun Dam Marcellusside, CO 42503 , Address: Road 3, Gateway Tower, 56777, Lennyside, Helena 55 East Gate Manchester, 111 3EE , Great Example VAT number: FR542122 Company number: 12345678 VAT number: 999 3333 11 Bank account sort code: 10-20-30 Bank account no:: 12345678 IBAN: IBANI23123123123123123 BIC: 1235912 No Service Amount (USD) Service Yadira DuBuque 289.40 Subtotal (USD): 289.40 VAT (1.659): 4.78 Invoice Total (USD): 294.18 Invoice has been paid via Stripe . Ser vice Provider LTD director: Amazing Person Dhd4Our final result was this:
[ ['Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount'], ['QAP321319', 'Great Example VAT number: FR542122 Company number: 12345678', '289.40', 'FR542122 Company number: 12345678', '1.659', '4.78', '294.18'], ['QAP321320', 'Turkey', '111.79', 'IT123156', '6.059', '6.76', '118.55'], ['QAP321318', 'Bahrain', '13.64', 'DE969696', '12.629', '1.72', '15.36'], ['QAP321316', 'Great Example VAT number: PL12313 Company number: 12345678', '707.21', 'PL12313 Company number: 12345678', '11.00%', '77.79', '785.00'], ['QAP321317', 'Bahamas', '66.68', 'NL123125', '15.239', '10.16', '76.84']]But here we were quick to note one thing - there is a lot of misreading! For example, our VAT % is read as 12.629 instead of 12.62. So we had to be careful with this.
One cool thing we can do here is to use the bbox coordinates to display the parsed text overlay on an image. To do this, we need a new library:
pip install cv2Then, we can write our code:
import easyocrimport pandas as pdimport globimport cv2import re def cleanup_text(text): # strip out non-ASCII text so we can draw the text on the image # using OpenCV return "".join([c if ord(c) < 128 else "" for c in text]).strip() def display_image(image, results): image_file = cv2.imread(image) for (bbox, text) in results: # unpack the bounding box (tl, tr, br, bl) = bbox tl = (int(tl[0]), int(tl[1])) tr = (int(tr[0]), int(tr[1])) br = (int(br[0]), int(br[1])) bl = (int(bl[0]), int(bl[1])) # cleanup the text and draw the box surrounding the text along # with the OCR'd text itself text = cleanup_text(text) cv2.rectangle(image_file, tl, br, (0, 255, 0), 2) cv2.putText(image_file, text, (tl[0], tl[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2) # show the output image_file cv2.imshow("Image", image_file) cv2.waitKey(0) data_output = [ [ 'Invoice number', 'Country', 'Subtotal amount', 'VAT ID number', 'VAT %', 'VAT Amount', 'Total amount', ]] img = glob.glob('invoices_images/*.jpg') for i, image in enumerate(img): reader = easyocr.Reader(['en'], gpu=True) results = reader.readtext( image, # Paragraph is needed to get text grouped together paragraph=True, # X_threshold is needed to get text grouped together # For example, address fields with high X_threshold will be grouped together # and will be returned as one text. This is not the desired outcome. # Lowering the X_threshold will return the address fields as separate text, which is also bad! # PS. Play around with the X_threshold to see the results. x_ths=0.3 ) df = pd.DataFrame(results, columns=['bbox', 'text']) df.drop(columns=['bbox'], inplace=True) text = '\n\n'.join(df['text'].tolist()) print(text) invoice_number = re.search(r'No.\s*(.+?)\s*\n', text).group(1).strip() country = re.search(r'Address:\s*(.+?)\s*\n\n', text, re.DOTALL).group(1).split(',')[-1].strip() subtotal_amount = re.search(r'Subtotal \(USD\):\s*(.+?)\s*\n', text).group(1).strip() search_vat_number = re.search(r'VAT number:\s*(.+?)\s*\n', text) if search_vat_number and search_vat_number.group(1) != '999 3333 11': vat_id_number = search_vat_number.group(1).strip() else: vat_id_number = None # Our OCR reader sometimes treats % as 9... So our Regex needs [%9] to match both vat_information = re.search(r'VAT \((.+?[%9])\):\s*(.+?)\s*\n', text) if not vat_information: # Sometimes, it decides to not treat `0.00` as a number, so we need to handle that print('VAT information not found for invoice: ' + image) vat_percent = 0 vat_amount = 0 else: vat_percent = vat_information.group(1).strip() vat_amount = vat_information.group(2).strip() total_amount = re.search(r'Invoice Total \(USD\):\s*(.+?)\s*\n', text).group(1).strip() data_output.append([ invoice_number, country, subtotal_amount, vat_id_number, vat_percent, vat_amount, total_amount, ]) # Uncomment to display image with bounding boxes display_image(image, results) print(data_output)Once we ran this, we got this output:

This is a very cool way to use our reader to see where and what was parsed!
The last thing we want to mention is that this library is very slow. We got an average of:
Runtime: 15.05s user 8.27sWhich is a lot slower than Pytesseract. That might not be an issue for you, but it's something to remember.
Alternative 2: Keras OCR
The last library we tried was Keras OCR. This library differs from the others because it reads text as individual blocks. This means that our output looks like this:
text bbox0 invoice [[740.0742, 141.61914], [911.3877, 141.61914],...1 qap321319 [[759.8514, 227.34422], [961.3338, 221.82414],...2 no [[694.3906, 228.41797], [749.21094, 228.41797]...3 20240110 [[746.92676, 310.64844], [906.81934, 310.64844...4 provider [[1025.5967, 415.7207], [1146.6582, 415.7207],...And if we look at an image overlay, it looks like this:
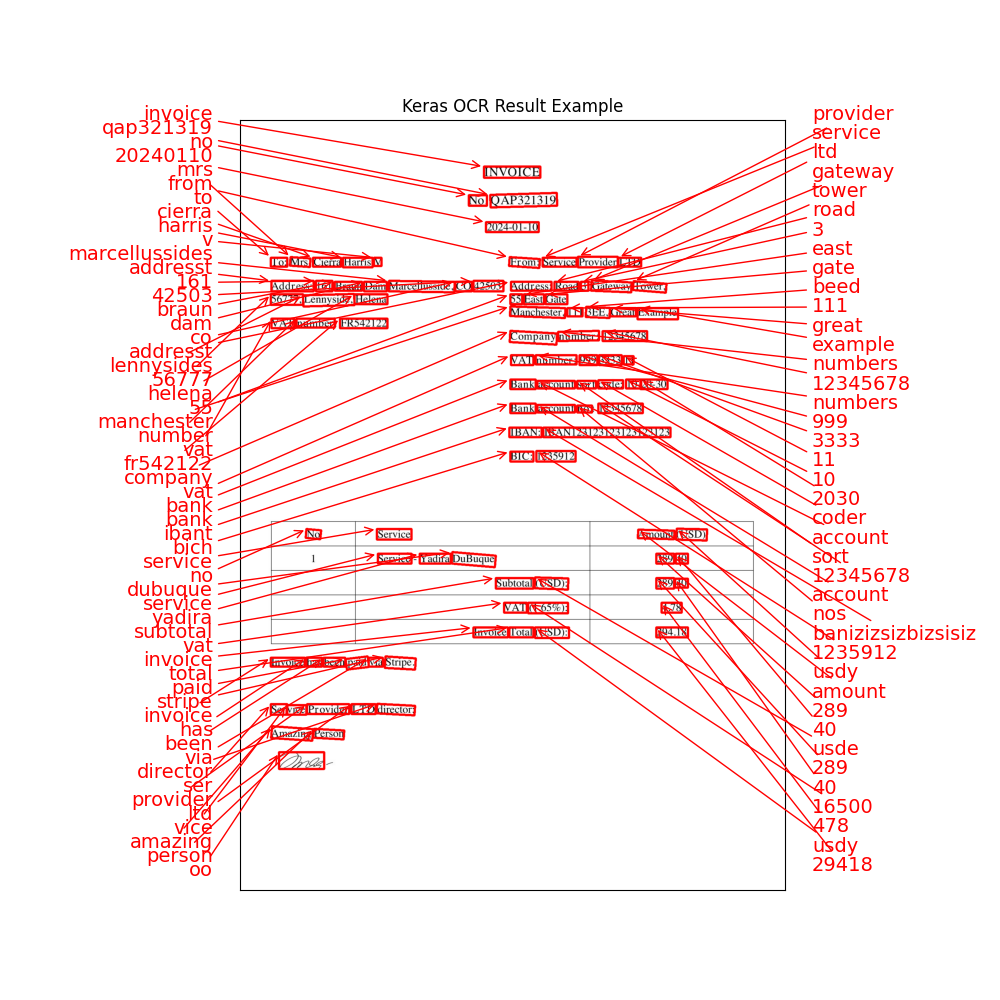
This can be useful if you want to parse individual blocks of text. Still, if you need to match patterns, you must write a complex combination algorithm.
In any case, its usage is pretty simple:
pip install keras-ocrpip install pandaspip install matplotlibAlong with: Tesseract-OCR Engine. You can find the installation instructions here.
Once these packages are installed, we can run our script:
import keras_ocrimport globimport pandas as pdimport matplotlib.pyplot as plt img = glob.glob('invoices_images/*.jpg') pipeline = keras_ocr.pipeline.Pipeline()results = pipeline.recognize( [img[0]], # Uncomment the next lines to see messier results # detection_kwargs={ # 'detection_threshold': 0.2, # 'text_threshold': 0, # 'link_threshold': 0, # 'size_threshold': 1, # },) df = pd.DataFrame(results[0], columns=['text', 'bbox'])pd.set_option('display.max_columns', None) # To display all columnsprint(df.head()) # Code to display image with bounding boxesfig, ax = plt.subplots(figsize=(10, 10))keras_ocr.tools.drawAnnotations(plt.imread(img[0]), results[0], ax=ax)ax.set_title('Keras OCR Result Example')plt.show()This will bring us the output we mentioned earlier. And if we uncomment the code to work with some detection parameters, we can get a messier output:
This, of course, can be our fault because we didn't fine-tune the parameters precisely. But that process was a bit complex, and even with a few hours - we could not get a better result than defaults and the box merging algorithm from StackOverflow.
Speed and Accuracy
This library was the slowest of them all. We got an average of:
Runtime: 63.74s user 8.95sWe suspect this is because it is the most powerful in seeing hard-to-read text. For example, this is one of the libraries that can deal with captchas, which is challenging. So, if you need to read hard-to-read text - this might be your library.
Conclusion (So Far)
The obvious takeaway is that there is no "best" OCR library. Each of them has their own pros and cons, and it all depends on your use case.
Pytesseract library worked best for us, but if you have a different use case, you could use EasyOCR or Keras OCR.
Also, the majority of the work on reading the text from images is not about using the OCR library, but rather about writing the correct regular expressions or parsing the text with other algorithms, to get the structured data as a result. We will cover various techniques for that, in the future lessons.
No comments or questions yet...