
In this tutorial, we will perform Excel data transformation with Python, based on the actual job from Upwork, which would earn $150.
In short, the goal is to read the Excel data and combine multiple lines related to the player entry into one line for each player.
From this:
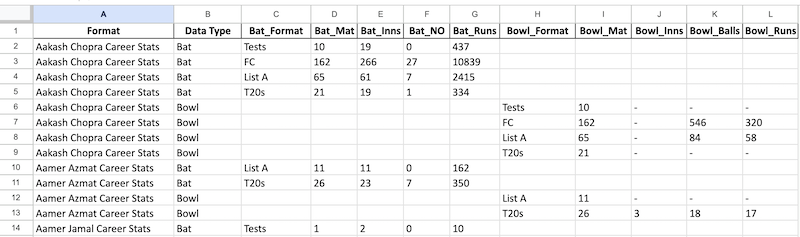
To this:

I will show you how to perform this task in ~30 lines of Python code.
We will transform the data with Python and save the result data into XLSX with the Pandas library.
Let's go!
Task Description
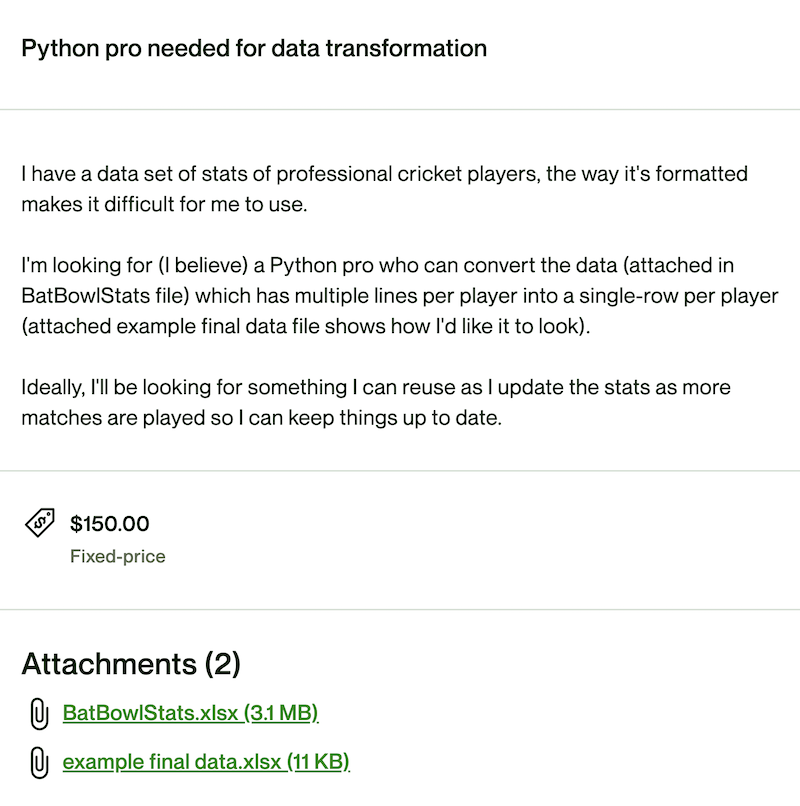
Here's the full job description from Upwork.
Let's look once again at the contents of the original BatBowlStats.xlsx:
I've simplified it a bit for this example: in the original file, there are 2x more columns, but those wouldn't change our approach.
See multiple rows for Aakash Chopra Career Stats? So, the task is to have ONE row for each player.
Here is the expected result:
You can find all those Excel files in this Google Drive folder.
This is a typical Python task about data transformation using lists/sets/dictionaries, so practicing with similar examples for future projects is very beneficial.
The plan consists of three steps:
- Populate Field Names from the Header
- Populating Data for Each Player
- Results into Excel with Pandas
Let's go!
Step 1. Populate Field Names from the Header
In the final result, we need to have the fields with all possible combinations of Bat_[field]_[type] and Bowl_[field]_[type].
We will process the type part when we read the Excel row by row, but just from the header row, we can populate the list of fields.
To read the Excel content, we will use the library called openpyxl-dictreader. You can install it with pip install openpyxl-dictreader command.
Here's the code to get the header row:
import openpyxl_dictreader reader = openpyxl_dictreader.DictReader("BatBowlStats-Short.xlsx", "Sheet1") field_names = reader.fieldnamesprint(field_names)Output:
['Format', 'Data Type', 'Bat_Format', 'Bat_Mat', 'Bat_Inns', 'Bat_NO', 'Bat_Runs', 'Bowl_Format', 'Bowl_Mat', 'Bowl_Inns', 'Bowl_Balls', 'Bowl_Runs']Next, the idea is to split those Bat_* and Bowl_* fields in two lists, combining them into one dictionary.
For that, we may use List Comprehensions in Python, adding a filter to take only the fields we need but also skipping the *_Format fields:
fields = { 'Bat': [x.split('_')[1] for x in field_names if x.startswith('Bat_') and x != 'Bat_Format'], 'Bowl': [x.split('_')[1] for x in field_names if x.startswith('Bowl_') and x != 'Bowl_Format']}print(fields)Output:
{'Bat': ['Mat', 'Inns', 'NO', 'Runs'], 'Bowl': ['Mat', 'Inns', 'Balls', 'Runs']}This structure is excellent! It will be helpful later when we loop through that dictionary, trying to find/fill the value for a specific field.
Step 2. Populating Data for Each Player
The next phase is reading the Excel content row by row and filling the specific values into the result dataset.
That dataset - we will call it players - will be a dictionary of key-value pairs. Each key will be a player name (for example, "Aakash Chopra Career Stats"), and each value will be a dictionary of many key-value pairs: fields with data.
Notice: if you're unfamiliar with the difference between dictionary/set/list in Python, here's my video about it.
Here's the code:
# We start with empty dictionary of playersplayers = {} # We will also collect all possible field formats along the wayfield_formats = set() for row in reader: # If it's the first row for that player, we create its dictionary if not row["Format"] in players: players[row["Format"]] = {} # Types: "Bat" or "Bowl" data_type = row["Data Type"] # Formats: "Tests", "FC", "List A", etc. data_format = row[f"{data_type}_Format"] field_formats.add(data_format) for field in fields[data_type]: players[row["Format"]][f"{data_type}_{field}_{data_format}"] = row[f"{data_type}_{field}"]The last line may be the hardest to understand. We are using f-strings to populate the names of the fields, like Bat_Runs_Tests.
For example, we're assigning the Excel column Bat_Runs value to the player's dictionary element of Bat_Runs_Tests.
As a result, we have a dictionary of 4774 players:
print(len(players)) # Output:4774Here's how one of them looks like:
print(players["Aakash Chopra Career Stats"])Output:
{'Bat_Mat_Tests': '10', 'Bat_Inns_Tests': '19', 'Bat_NO_Tests': '0', 'Bat_Runs_Tests': '437', 'Bat_Mat_FC': '162', 'Bat_Inns_FC': '266', 'Bat_NO_FC': '27', 'Bat_Runs_FC': '10839', 'Bat_Mat_List A': '65', 'Bat_Inns_List A': '61', 'Bat_NO_List A': '7', 'Bat_Runs_List A': '2415', 'Bat_Mat_T20s': '21', 'Bat_Inns_T20s': '19', 'Bat_NO_T20s': '1', 'Bat_Runs_T20s': '334', 'Bowl_Mat_Tests': '10', 'Bowl_Inns_Tests': '-', 'Bowl_Balls_Tests': '-', 'Bowl_Runs_Tests': '-', 'Bowl_Mat_FC': '162', 'Bowl_Inns_FC': '-', 'Bowl_Balls_FC': '546', 'Bowl_Runs_FC': '320', 'Bowl_Mat_List A': '65', 'Bowl_Inns_List A': '-', 'Bowl_Balls_List A': '84', 'Bowl_Runs_List A': '58', 'Bowl_Mat_T20s': '21', 'Bowl_Inns_T20s': '-', 'Bowl_Balls_T20s': '-', 'Bowl_Runs_T20s': '-'}Looks great, exactly what we needed!
We also have this set of field_formats:
print(field_formats)Output:
{'FC', 'List A', 'ODIs', 'T20Is', 'T20s', 'Tests', 'WODIs', 'WT20Is', 'WTests'}Now, the final step is to write the players' data into a new Excel file.
Step 3. Results into Excel with Pandas
Before building the final Exce from the players variable, we need to build the list of header columns separately.
This is where we utilize the same fields dictionary and field_formats list, performing a 3-level for loop.
headers = ['Format']for field_type in fields: for field_format in field_formats: for field in fields[field_type]: headers.append(f"{field_type}_{field}_{field_format}")print(headers)Output is a looooong list of 70+ columns:
['Format', 'Bat_Mat_Tests', 'Bat_Inns_Tests', 'Bat_NO_Tests', 'Bat_Runs_Tests', 'Bat_Mat_FC', 'Bat_Inns_FC', 'Bat_NO_FC', 'Bat_Runs_FC', 'Bat_Mat_List A', 'Bat_Inns_List A', 'Bat_NO_List A', 'Bat_Runs_List A', 'Bat_Mat_T20s', 'Bat_Inns_T20s', 'Bat_NO_T20s', 'Bat_Runs_T20s', 'Bat_Mat_T20Is', 'Bat_Inns_T20Is', 'Bat_NO_T20Is', 'Bat_Runs_T20Is', 'Bat_Mat_ODIs', 'Bat_Inns_ODIs', 'Bat_NO_ODIs', 'Bat_Runs_ODIs', 'Bat_Mat_WODIs', 'Bat_Inns_WODIs', 'Bat_NO_WODIs', 'Bat_Runs_WODIs', 'Bat_Mat_WT20Is', 'Bat_Inns_WT20Is', 'Bat_NO_WT20Is', 'Bat_Runs_WT20Is', 'Bat_Mat_WTests', 'Bat_Inns_WTests', 'Bat_NO_WTests', 'Bat_Runs_WTests', 'Bowl_Mat_Tests', 'Bowl_Inns_Tests', 'Bowl_Balls_Tests', 'Bowl_Runs_Tests', 'Bowl_Mat_FC', 'Bowl_Inns_FC', 'Bowl_Balls_FC', 'Bowl_Runs_FC', 'Bowl_Mat_List A', 'Bowl_Inns_List A', 'Bowl_Balls_List A', 'Bowl_Runs_List A', 'Bowl_Mat_T20s', 'Bowl_Inns_T20s', 'Bowl_Balls_T20s', 'Bowl_Runs_T20s', 'Bowl_Mat_T20Is', 'Bowl_Inns_T20Is', 'Bowl_Balls_T20Is', 'Bowl_Runs_T20Is', 'Bowl_Mat_ODIs', 'Bowl_Inns_ODIs', 'Bowl_Balls_ODIs', 'Bowl_Runs_ODIs', 'Bowl_Mat_WODIs', 'Bowl_Inns_WODIs', 'Bowl_Balls_WODIs', 'Bowl_Runs_WODIs', 'Bowl_Mat_WT20Is', 'Bowl_Inns_WT20Is', 'Bowl_Balls_WT20Is', 'Bowl_Runs_WT20Is', 'Bowl_Mat_WTests', 'Bowl_Inns_WTests', 'Bowl_Balls_WTests', 'Bowl_Runs_WTests']Yup, this is how many columns we will have in the final Excel. Next, write data to it.
Various libraries can help us to write the players dictionary to Excel. But, instead of using specific Excel libraries, I chose Pandas library: it works with dataframes that are also easy to write to Excel with just df.to_excel() method.
So, we need to install that library with pip install pandas.
Then, we transform our data into the DataFrame and then call the function to export to Excel:
import pandas as pd df = pd.DataFrame([{**player, 'Format': name} for name, player in players.items()], columns=headers)df.to_excel('final_data_pandas.xlsx', sheet_name='Sheet 1', index=False)Explanation:
- We iterate through
players.items()and build a list, each item being a dictionary. That dictionary consists of all fields in theplayer, adding one more column as a key-value pair of'Format': name. - That
**playersyntax is an operator to pack/unpack the dictionary. - We save that DataFrame to Excel, with providing
index=False. Without that parameter, Pandas would generate an additional first column with an enumeration of the rows: 0, 1, 2, etc.
And... that's it!
Here's the result Excel file:
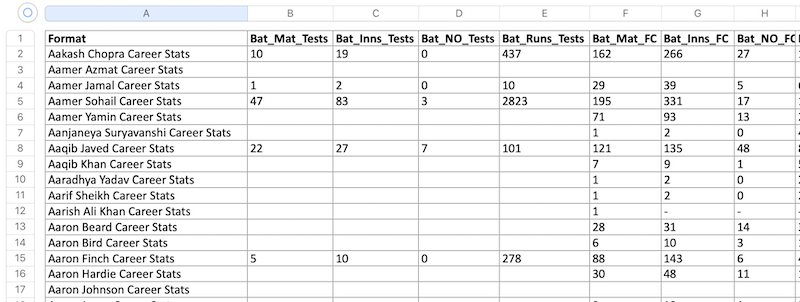
Here's the full script:
import openpyxl_dictreaderimport pandas as pd reader = openpyxl_dictreader.DictReader("BatBowlStats-Short.xlsx", "Sheet1") field_names = reader.fieldnames fields = { 'Bat': [x.split('_')[1] for x in field_names if x.startswith('Bat_') and x != 'Bat_Format'], 'Bowl': [x.split('_')[1] for x in field_names if x.startswith('Bowl_') and x != 'Bowl_Format']} players = {}field_formats = set() for row in reader: if not row["Format"] in players: players[row["Format"]] = {} data_type = row["Data Type"] # "Bat" or "Bowl" data_format = row[f"{data_type}_Format"] field_formats.add(data_format) for field in fields[data_type]: players[row["Format"]][f"{data_type}_{field}_{data_format}"] = row[f"{data_type}_{field}"] headers = ['Format']for field_type in fields: for category in field_categories: for field in fields[field_type]: headers.append(f"{field_type}_{field}_{category}") df = pd.DataFrame([{**player, 'Format': name} for name, player in players.items()], columns=headers)df.to_excel('final_data_pandas.xlsx', sheet_name='Sheet 1', index=False)You can experiment with this script using the Excel files in this Google Drive folder.
No comments or questions yet...