Python Data Pre-Processing Example: Multiple CSVs into Single File

Imagine that you need to analyze the data for multiple years, and the client gives the data in multiple CSV files, one per year. Even worse, some columns in some years are in a different format. The task for data pre-processing, huh? Let's write a Python script for it.
Here's the format for the file for the year 2016:

Take a closer look at three fields about the levels (junior/mid/senior):
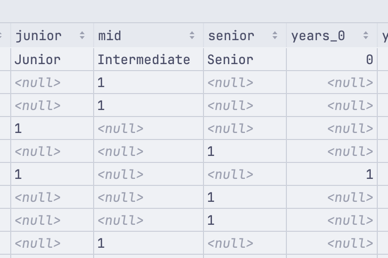
And another closer look at the fields about the years of experience - from 0 to 10:
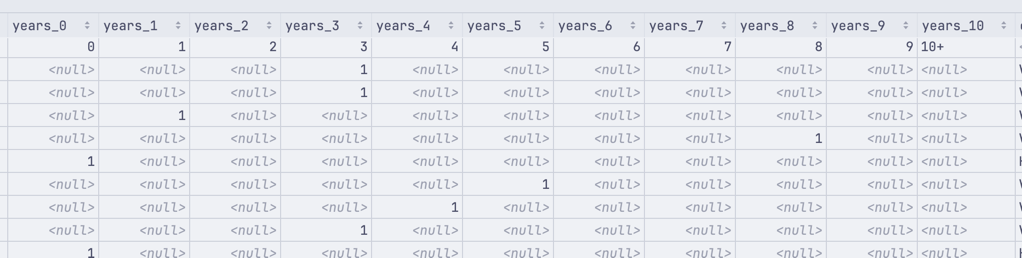
And here's the format for the year 2023:
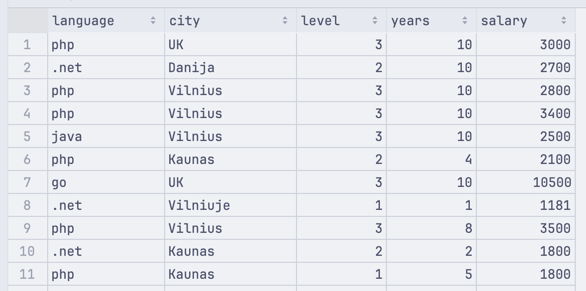
See the difference and the problem?
We actually have four tasks here:
- The first file has columns like "level" and "years" split into multiple columns, so we need to combine them and assign the value of 1/2/3 for level and 1-10 for years of experience
- Also, while merging the files into one CSV, we need to add a
survey_yearcolumn. - Programming languages are provided comma-separated: we need to take only the first one
- Some cities are provided with typos: we need to replace them with the correct names
The final result should be this:
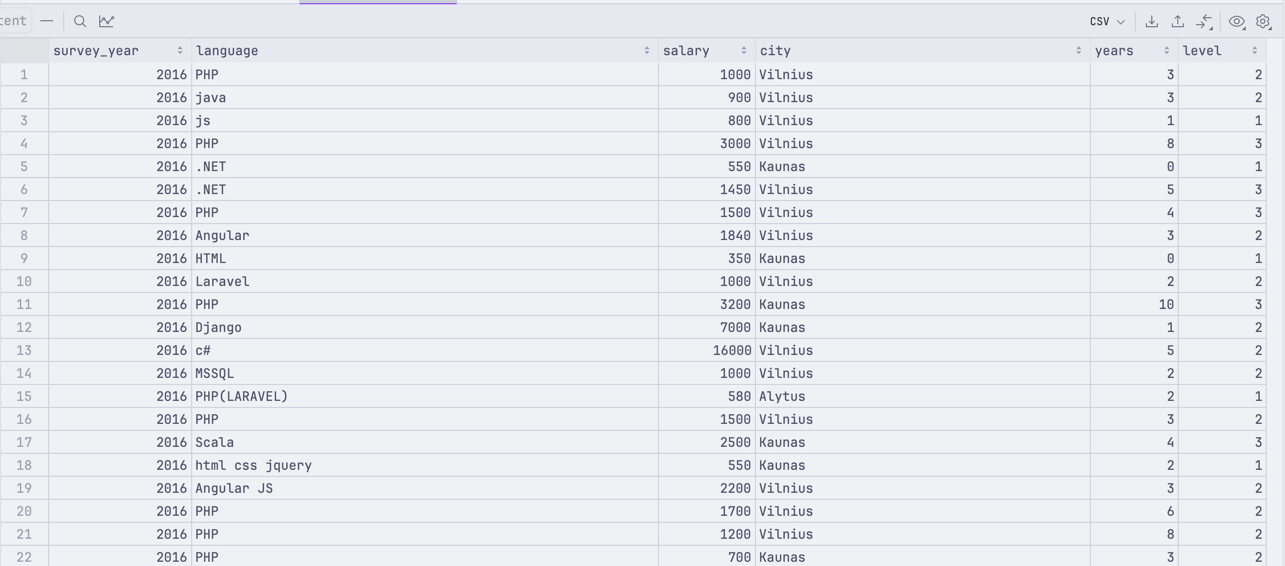
Step 1. Simple Loop.
Let's start by importing a library and writing a structure for our data:
import csv # This is how our data will look at the exportdatalist = [[ 'survey_year', 'language', 'salary', 'city', 'years', 'level']]Next, we need to create a list of files that we want to merge:
# ... # Files that we want to mergefiles = { 2016: 'data/rawSource/salary-2016.csv', 2017: 'data/rawSource/salary-2017.csv', 2018: 'data/rawSource/salary-2018.csv', 2019: 'data/rawSource/salary-2019.csv', 2020: 'data/rawSource/salary-2020.csv', 2021: 'data/rawSource/salary-2021.csv', 2022: 'data/rawSource/salary-2022.csv', 2023: 'data/rawSource/salary-2023.csv',}And, of course, we need to read the data from the files:
# ... # Loop through the files and read the datafor year, file in files.items(): # Open the file with open(file, newline='') as csvfile: # Read the file reader = csv.DictReader(csvfile) # Loop through the rows for row in reader: # Add the row to our data list datalist.append([ year, row['language'], row['salary'], row['city'], row['years'], row['level'] ])Now, if we run the script, we will get an error:
Traceback (most recent call last): File "/transforming-csv-to-a-common-format/mergeCSV.py", line 52, in <module> row['years'],KeyError: 'years'This is because we have different columns in our files. Just take a look at the 2016 and 2023 files:
2016
"language",junior,mid,senior,"years_0","years_1","years_2","years_3","years_4","years_5","years_6","years_7","years_8","years_9","years_10","city","salary",Junior,Intermediate,Senior,0,1,2,3,4,5,6,7,8,9,10+,,PHP,,1,,,,,1,,,,,,,,Vilnius,1000Java,,1,,,,,1,,,,,,,,Vilnius,9002023
language,city,level,years,salaryphp,UK,3,10,3000.net,Danija,2,10,2700php,Vilnius,3,10,2800As you can see, we have different columns in both files. Our script currently expects the 2023 file, but that failed in 2016.
Step 2. Functions to Transform Years/Level
We can define the functions to change the values based on other values:
# ...datalist = [[ # ...]] def get_level(row): if row['junior']: return 1 if row['mid']: return 2 if row['senior']: return 3 return 0 def get_years(row): for y in range(0, 11): if row[f'years_{y}']: return y files = { 2016: 'data/rawSource/salary-2016.csv', 2017: 'data/rawSource/salary-2017.csv', 2018: 'data/rawSource/salary-2018.csv', 2019: 'data/rawSource/salary-2019.csv', 2020: 'data/rawSource/salary-2020.csv', 2021: 'data/rawSource/salary-2021.csv', 2022: 'data/rawSource/salary-2022.csv', 2023: 'data/rawSource/salary-2023.csv',} for year, file in files.items(): with open(file, newline='') as csvfile: reader = csv.DictReader(csvfile) for row in reader: datalist.append([ year, row['language'], row['salary'], row['city'], get_years(row) if 'years' not in row else row['years'], get_level(row) if 'years' not in row else row['level'] ])Here's what we did:
- We created a
get_level()function that returns the level of the developer based on the columns (this applies to files that match the 2016 format) - We created a
get_years()function that returns the years of the developer based on the columns (this applies to files that match the 2016 format) - We check if the
yearscolumn exists in our loop. If it does not - we use our custom functions to get the data. If it does - we use the column directly.
Running this now, we should not see any errors. However, we still have more work to do.
Step 3. Merging Similar Cities and Languages
Here's the plan of the next step:
- Similar city names should be merged
- Similar language names should be merged
- Multi-language developers should get their own row (or not, based on the settings)
We've manually identified the typos and different ways of writing the city/language names, and we create lists from them.
# ... # Set this to control how the data is split# True -> Split language into individual languages# False -> Take the first language and ignore the restsplit_language_into_individual_languages = True # Normalize the city namesvilnius_names = ['Vilniuj', 'Vilniua', 'VILNIUJE', 'VILNIUS', 'vilnius', 'Vilniuje']kaunas_names = ['KAUNAS', 'kaunas', 'Kaune', 'Kns']klaipeda_names = ['Klaipėda', 'Klaipeda', 'Klaipėdoje', 'Klaipedoje'] # Normalize the language namesphp_names = ['PHP', 'php', 'Php']js_names = ['js', 'JS', 'JavaScript', 'javascript']dotnet_names = ['.net', 'dotnet', 'Dotnet', 'DotNet']java_names = ['java', 'Java', 'JAVA', 'Java (Android)'] # Clean the data:# Check if salary is a number. If not - remove the row (people who provided a salary range)# Split languages into individual languages (if enabled)for i, row in enumerate(datalist): if i == 0: continue if type(row[2]) is not int: salary = [x for x in row[2] if x.isdigit()] salary = ''.join(salary) if salary.isdigit(): datalist[i][2] = int(salary) else: datalist.pop(i) continue # Split languages into individual languages if split_language_into_individual_languages: languages = row[1].split(',') if len(languages) > 1: for language in languages: datalist.append([ row[0], language.strip(), row[2], row[3], row[4], row[5] ]) else: # Take the first language and ignore the rest languages = row[1].split(',')[0] datalist[i][1] = languages # Loop through the data and normalize the city names and language namesfor i, row in enumerate(datalist): if i == 0: continue if row[1] == '': datalist.pop(i) if row[3] in vilnius_names: datalist[i][3] = 'Vilnius' elif row[3] in kaunas_names: datalist[i][3] = 'Kaunas' elif row[3] in klaipeda_names: datalist[i][3] = 'Klaipeda' if row[1] in php_names: datalist[i][1] = 'PHP' elif row[1] in js_names: datalist[i][1] = 'js' elif row[1] in dotnet_names: datalist[i][1] = '.net' elif row[1] in java_names: datalist[i][1] = 'java'Step 4. Write Data into a New CSV
Last but not least - we need to export the data:
# ... with open('data/salaries.csv', 'w', newline='') as csvfile: writer = csv.writer(csvfile) writer.writerows(datalist) print('Done')And now, if we run the script - we should get a salaries.csv file with all the data:
Full Code
import csv datalist = [[ 'survey_year', 'language', 'salary', 'city', 'years', 'level']] def get_level(row): if row['junior']: return 1 if row['mid']: return 2 if row['senior']: return 3 return 0 def get_years(row): for y in range(0, 11): if row[f'years_{y}']: return y files = { 2016: 'data/rawSource/salary-2016.csv', 2017: 'data/rawSource/salary-2017.csv', 2018: 'data/rawSource/salary-2018.csv', 2019: 'data/rawSource/salary-2019.csv', 2020: 'data/rawSource/salary-2020.csv', 2021: 'data/rawSource/salary-2021.csv', 2022: 'data/rawSource/salary-2022.csv', 2023: 'data/rawSource/salary-2023.csv',} for year, file in files.items(): with open(file, newline='') as csvfile: reader = csv.DictReader(csvfile) for row in reader: datalist.append([ year, row['language'], row['salary'], row['city'], get_years(row) if 'years' not in row else row['years'], get_level(row) if 'years' not in row else row['level'] ]) # Set this to control how the data is split# True -> Split language into individual languages# False -> Take the first language and ignore the restsplit_language_into_individual_languages = False # Normalize the datavilnius_names = ['Vilniuj', 'Vilniua', 'VILNIUJE', 'VILNIUS', 'vilnius', 'Vilniuje']kaunas_names = ['KAUNAS', 'kaunas', 'Kaune', 'Kns']klaipeda_names = ['Klaipėda', 'Klaipeda', 'Klaipėdoje', 'Klaipedoje'] php_names = ['PHP', 'php', 'Php']js_names = ['js', 'JS', 'JavaScript', 'javascript']dotnet_names = ['.net', 'dotnet', 'Dotnet', 'DotNet']java_names = ['java', 'Java', 'JAVA', 'Java (Android)'] for i, row in enumerate(datalist): if i == 0: continue if type(row[2]) is not int: salary = [x for x in row[2] if x.isdigit()] salary = ''.join(salary) if salary.isdigit(): datalist[i][2] = int(salary) else: datalist.pop(i) continue # Split languages into individual languages if split_language_into_individual_languages: languages = row[1].split(',') if len(languages) > 1: for language in languages: datalist.append([ row[0], language.strip(), row[2], row[3], row[4], row[5] ]) datalist.pop(i) else: # Take the first language and ignore the rest languages = row[1].split(',')[0] datalist[i][1] = languages for i, row in enumerate(datalist): if i == 0: continue if row[1] == '': datalist.pop(i) if row[3] in vilnius_names: datalist[i][3] = 'Vilnius' elif row[3] in kaunas_names: datalist[i][3] = 'Kaunas' elif row[3] in klaipeda_names: datalist[i][3] = 'Klaipeda' if row[1] in php_names: datalist[i][1] = 'PHP' elif row[1] in js_names: datalist[i][1] = 'js' elif row[1] in dotnet_names: datalist[i][1] = '.net' elif row[1] in java_names: datalist[i][1] = 'java' with open('data/salaries.csv', 'w', newline='') as csvfile: writer = csv.writer(csvfile) writer.writerows(datalist) print('Done')
No comments or questions yet...