
Python is an excellent language for big datasets. But did you know that Python has a built-in module for collections of data? Take a look at the following example of how it can simplify your code:

We went from 6 lines of code to just 2! But that's not all. We can look at other examples in collections and see how to use them!
In this tutorial, we will cover the following classes from the collections module:
-
Counter -
DefaultDict -
Deque -
NamedTuple
Counter - Simplified Counting
It is common to count things in data projects. From counting the number of times a word appears in a text (for ML projects) to counting the number of distinct values in a list. In our example, we have the following list:
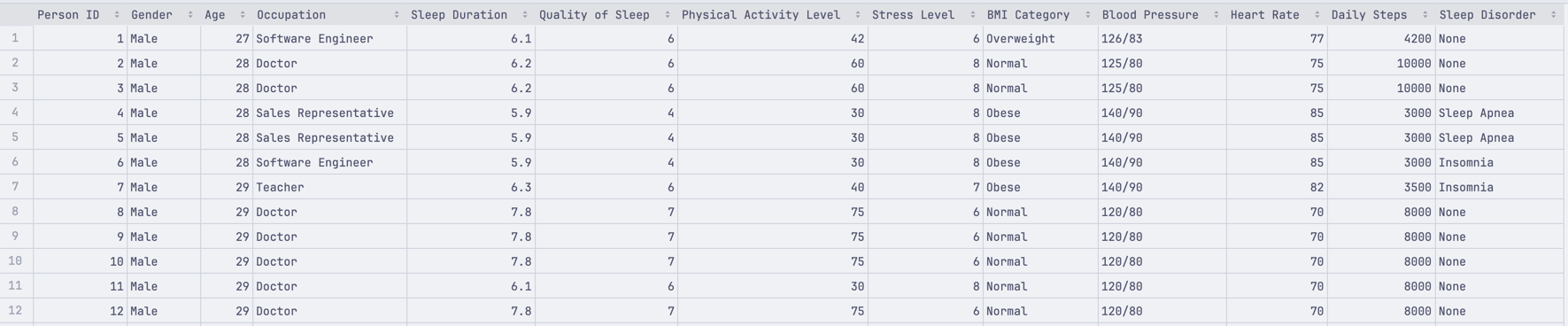
And we have loaded it into a simple list:
import csv def dataset(column_index): data = [] with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data.append(row[column_index]) return dataWe want to count how many Males and Females we have in our dataset. We can do this manually:
# ... def count_manually(data): count = {} for element in data: count[element] = count.get(element, 0) + 1 return count print(count_manually(dataset(1))) # We want to count "Gender" column from our CSV file # Output:# {'Male': 189, 'Female': 184}Or we can use the Counter class from the collections module:
from collections import Counter # ... print(Counter(dataset(1)).most_common()) # We want to count "Gender" column from our CSV file # Output:# [('Male', 189), ('Female', 184)]This helped us reduce the code complexity and made it easier to understand. But what if we want to count the number of different professions in our dataset? Here's how this looks with Counter:
# ... print(Counter(dataset(3)).most_common()) # We want to count "Occupation" column from our CSV fileAnd we should get the following output:
[('Nurse', 72), ('Doctor', 71), ('Engineer', 63), ('Lawyer', 46), ('Teacher', 40), ('Accountant', 37), ('Salesperson', 32), ('Software Engineer', 4), ('Scientist', 4), ('Sales Representative', 2), ('', 1), ('Manager', 1)]Last, we can even take the top 5 professions in our dataset:
print(Counter(dataset(3)).most_common(5)) # We want to count "Occupation" column from our CSV file and limit it to top 5And we should get the following output:
[('Nurse', 72), ('Doctor', 71), ('Engineer', 63), ('Lawyer', 46), ('Teacher', 40)]It's that simple! We did not have to write a single line of code to iterate over our dataset manually. We just used the Counter class designed to do this for us.
DefaultDict - Dictionary with Default Values
Working with dict is common in Python. Same as seeing the following error (if you are not careful):
Traceback (most recent call last): File "/python/python-collections/defaultdict.py", line 27, in <module> print(dataset(use_default_dict=False)['1555112']) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^KeyError: '1555112'This happens because we are trying to access a key that does not exist in our dictionary. We can solve this using the defaultdict class from the collections module. Here's how we can use it:
from collections import defaultdictimport csv def dataset(): def print_default(): return 'N/A' # Default value for missing data data = defaultdict(print_default) with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data[row[0]] = row return data print(dataset()['1']) # Returns the entire row for the key 1print(dataset()['1555112']) # Returns the default value for missing data (N/A)Specifically, in this example, we need to focus on this part of the code:
# ...def print_default(): return 'N/A' # Default value for missing data data = defaultdict(print_default)# ...It allows us to tell what is the default value if a key is not found. Let's see the output of our code above:
['1', 'Male', '27', 'Software Engineer', '6.1', '6', '42', '6', 'Overweight', '126/83', '77', '4200', 'None']N/AAs you can see, we have a row for our dataset()['1'] being printed and the default value for dataset()['1555112'] being printed as well. This is a great way to avoid the KeyError we saw before and make our code more robust.
Deque - Double-Ended Queue
A deque is a double-ended queue. It can be used to add or remove elements from both ends, so it's a great way to work with elements that need to be added or removed from the beginning or the end of a list. Here's an example of how we can use it:
from collections import dequeimport csv def dataset(column_index): data = deque() with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data.append(row[column_index]) return data deque_list = dataset(1) print(deque_list)print('-' * 50 + ' Adding more elements to the deque list ' + '-' * 50)deque_list.append("new data")deque_list.appendleft("first data")print(deque_list)Main code to focus on:
# ...data = deque() # ...data.append(row[column_index]) # ... deque_list.append("new data")deque_list.appendleft("first data")This simple example allows us to append or "prepend" (add at the start of the list) any new elements we want. Here's the output of our code:
deque(['Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male'])-------------------------------------------------- Adding more elements to the deque list --------------------------------------------------deque(['first data', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'Male', 'new data'])As you can see, we originally had one dataset with 10 elements. Then, we called append() and appendleft() to add new elements to our list. This added two different elements at the start and end of our list, which would not be possible using a regular list. We can only append() with a standard list, but there is no appendleft() method.
NamedTuple - Tuple with Named Fields
Sometimes, we need to work with tuples, but accessing the fields by index can be confusing. Especially when we have a lot of fields. This is where NamedTuple comes in. It allows us to access the fields by name. Here's an example:
from collections import namedtupleimport csv def collections_dataset(): sleep_data = namedtuple('patient_data', [ 'gender', 'age', 'sleep_duration', ]) data = [] with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data.append( sleep_data( gender=row[1], age=row[2], sleep_duration=row[4] ) ) patients = namedtuple('patients', ['patients']) return patients(data) collection_dataset = collections_dataset()print(collection_dataset.patients[0].sleep_duration)The central part of the code is this:
# ... sleep_data = namedtuple('patient_data', [ 'gender', 'age', 'sleep_duration',]) data = [] # ... data.append( sleep_data( gender=row[1], age=row[2], sleep_duration=row[4] )) # ... patients = namedtuple('patients', ['patients']) return patients(data)This lets us define a named tuple sleep_data with our fields. Then, on assignment, we can assign each field by the name instead of an index or a key. If we compare it to a regular tuple, this has a few advantages. The biggest one is the auto-completion:
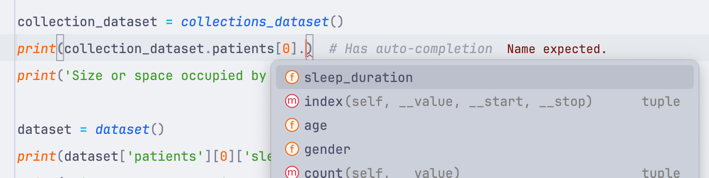
But of course, this is the biggest from a development perspective. It can make our code take up less RAM and be faster. Here's how we tested it:
import sysfrom collections import namedtupleimport csv def collections_dataset(): sleep_data = namedtuple('patient_data', [ 'gender', 'age', 'sleep_duration', ]) data = [] with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data.append( sleep_data( gender=row[1], age=row[2], sleep_duration=row[4] ) ) patients = namedtuple('patients', ['patients']) return patients(data) def dataset(): data = [] with open('data/healthdata.csv', 'r') as f: contents = csv.reader(f) next(contents) # Skip the header for row in contents: data.append( { 'gender': row[1], 'age': row[2], 'sleep_duration': row[4] } ) return { 'patients': data } collection_dataset = collections_dataset()print(collection_dataset.patients[0].sleep_duration) # Has auto-completionprint('Size or space occupied by dictionary', sys.getsizeof(collection_dataset)) dataset = dataset()print(dataset['patients'][0]['sleep_duration']) # No auto-completionprint('Size or space occupied by dictionary', sys.getsizeof(dataset))In the end, you can see that we called sys.getsizeof() to retrieve the size of our datasets. This is what we got:
6.1Size or space occupied by dictionary 486.1Size or space occupied by dictionary 184Our named tuple took up less space in memory than our regular dictionary. Of course, this depends on how you configure your named tuple. Still, it's an excellent example of how it can be more efficient and developer-friendly.
No comments or questions yet...