
When working on Dataset, it is common to find empty columns or even rows. This can happen for various reasons, but do you know how to search for them and replace them with Pandas DataFrame?
Finding Empty Rows and Columns
To look for empty rows and columns, we have a few options:
- Using
isnull()method with.sum()or.any()method - Calculating the percentage of empty rows and columns
- Using
isnull()as a mask to filter empty rows
Let's take a look at each of them individually.
Example 1: Searching with isnull()
This is probably the most common way to look for empty columns, as it is simple and easy to use:
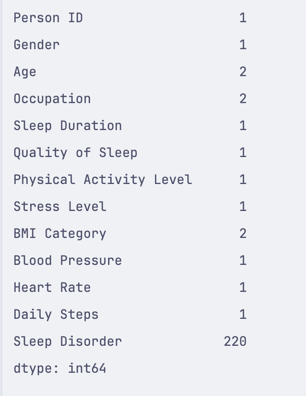
import pandas df = pandas.read_csv('healthdata.csv') print(df.isnull().sum())This will return the number of empty rows for each column in the DataFrame. You can read it as "for each column, how many empty rows are there?".
But if you want to know if there are any empty rows at all, you can use the .any() method:
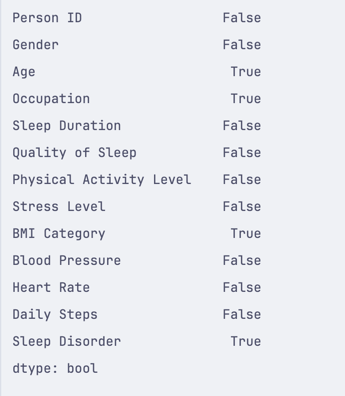
# ...print(df.isnull().any())This will return a boolean value for each column, indicating if there are any empty rows in it.
You can also see people using code that looks like this:
# ...print(df.isna().sum())print(df.isna().any())This is because isnull() and isna() are the same method. To be exact, isnull() is an alias for isna().
You can take a look at an example of this online in Kaggle - Sleep Health Lifestyle Eda Visualization
Example 2: Calculating the Percentage of Empty Rows
Another way to look for empty rows is to calculate how many are empty. This can be done with a simple for loop:
- Loop over each column
- Calculate the percentage of empty rows
- If the percentage is greater than 0, print the column name and the percentage
import pandas df = pandas.read_csv('healthdata.csv') for i in df.columns: null_rate = df[i].isnull().sum() / len(df) * 100 if null_rate > 0: print(f"{i} null rate: %{null_rate:.2f}")This will return the name of the column and the percentage of empty rows in it:
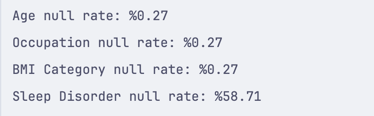
This is an excellent way to determine how accurate your Dataset might be. If you see a column with a high percentage of empty rows, you should look closely at it and decide if you want to keep it.
You can take a look at an example of this online in Kaggle - Netflix Data Visualization
Example 3: Using isnull() as a Mask
Now that we know how to search for empty columns, we should also know how to filter empty rows. This can be done by using the isnull() method as a mask:
import pandas df = pandas.read_csv('healthdata.csv') null_mask = df.isnull().all(axis=1)null_rows = df[null_mask]print(null_rows)Once we run this code, we will get a DataFrame with only the empty rows:
![]()
This is an excellent way to select only the empty rows and decide what to do with them. You might want to check the data source and see if you can fill them with some data or if you should drop them.
Replacing Empty Columns
Now that we know how to search for empty rows and columns, we should also know how to replace them. Here are a few ways to do it:
- Using the
fillna()method to fill empty rows with a value - Using the
dropna()method to drop empty rows and columns
Example 1: Using fillna() - Filling All Empty Columns
Most of the time, we need to take empty rows and fill them with some value. This can be anything, from a simple 0 to a more complex value. Here's how to do it:
import pandas df = pandas.read_csv('healthdata.csv') df.fillna(0, inplace=True)This will fill all empty rows with the value 0:
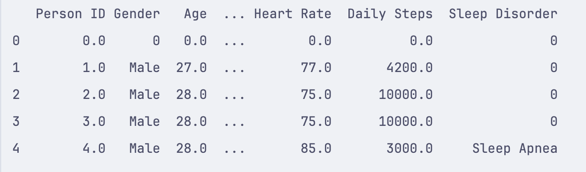
But this changes the original DataFrame because we used the inplace=True parameter. Suppose you don't want to change the original DataFrame. In that case, you can use the inplace=False parameter or assign the result to a new variable:
import pandas df = pandas.read_csv('healthdata.csv') new_df = df.fillna(0)This will create a new DataFrame with the empty rows filled with 0, and the original DataFrame will remain unchanged.
Example 2: Using fillna() - Filling Specific Columns
If filling all empty rows with the same value is not what you want, you can also fill specific columns with specific values:
import pandas df = pandas.read_csv('healthdata.csv') df['Sleep Disorder'].fillna('No', inplace=True)This will fill all empty rows in the Sleep Disorder column with the value No:
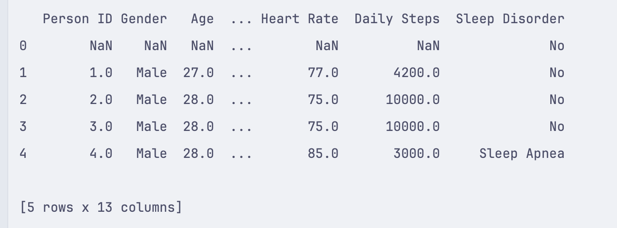
You can also use the inplace=False parameter or assign the result to a new variable:
import pandas df = pandas.read_csv('healthdata.csv') new_df = df['Sleep Disorder'].fillna('No')Example 3: Using dropna() - Dropping Empty Rows and Columns
You can drop them if you don't want to fill empty rows. This can be done with the dropna() method:
import pandas df = pandas.read_csv('healthdata.csv') df.dropna(inplace=True)This will drop all empty rows and columns from the DataFrame:
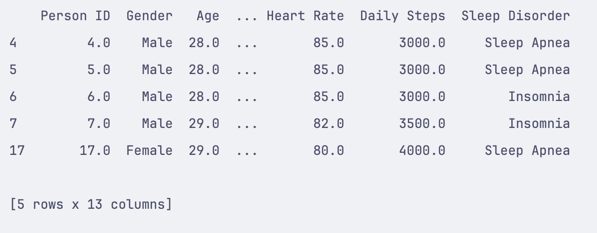
Just like the fillna() method, you can use the inplace=False parameter or assign the result to a new variable:
import pandas df = pandas.read_csv('healthdata.csv') new_df = df.dropna()Wait, What is Empty? None vs NaN vs Empty String
When we talk about empty rows, we have a few options to consider:
-
None- This is the Python way to represent an empty value -
NaN- This is the Pandas' way to represent an empty value - '' - This is an empty string, which is different from
NoneandNaN
Let's look at how this looks in a CSV file:
"",,,,,,,,,1,Male,27,Software Engineer,6.1,6,42,6,Overweight,126/83,77,4200,''2,Male,28,Doctor,6.2,6,60,8,Normal,125/80,75,10000,3,Male,28,Doctor,6.2,6,60,8,Normal,125/80,75,10000,NaNCan you spot all empty values? Let's take a look at them:
- First line - Both
""and,,,,,are empty values - Second line - The last value is an empty string - not an empty value!
- Third line - The last value is
Nonewhich is an empty value - Fourth line - The last value is
NaN, which is an empty value
Let's take a look at how Pandas see them:
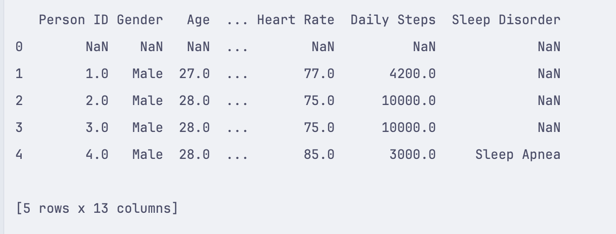
import pandas df = pandas.read_csv('healthdata.csv') print(df.head())This will return the following DataFrame:
![]()
Now, if we try to replace them with a value, we can see how they are different:
import pandas df = pandas.read_csv('healthdata.csv') df.fillna(0, inplace=True)This will fill all empty values with 0:
![]()
But wait, what is this? The last value in the second line is still an empty string ''! Pandas see it as a different value from None and NaN. This is why knowing what you are working with and how to handle it is essential.
Let's handle it:
import pandas df = pandas.read_csv('healthdata.csv') df.fillna(0, inplace=True)df['Sleep Disorder'].replace(to_replace="''", value=0, inplace=True)This will replace '' with 0:
![]()
No comments or questions yet...